init
@@ -0,0 +1,708 @@
|
||||
---
|
||||
title: JVM中篇
|
||||
date: 2024-08-25
|
||||
tags: [JVM]
|
||||
---
|
||||
|
||||
|
||||
## JVM内存管理
|
||||
|
||||
在传统的C/C++开发中,我们经常通过使用申请内存的方式来创建对象或是存放某些数据,但是这样也带来了一些额外的问题,我们要在何时释放这些内存,怎么才能使得内存的使用最高效,因此,内存管理是一个非常严肃的问题。
|
||||
|
||||
比如我们就可以通过C语言动态申请内存,并用于存放数据:
|
||||
|
||||
```C
|
||||
\#include <stdlib.h>#include <stdio.h>int main(){
|
||||
//动态申请4个int大小的内存空间
|
||||
int* memory = malloc(sizeof(int) * 4);
|
||||
//修改第一个int空间的值
|
||||
memory[0] = 10;
|
||||
//修改第二个int空间的值
|
||||
memory[1] = 2;
|
||||
//遍历内存区域中所有的值
|
||||
for (int i = 0;i < 4;i++){
|
||||
printf("%d ", memory[i]);
|
||||
}
|
||||
//释放指针所指向的内存区域
|
||||
free(memory);
|
||||
//最后将指针赋值为NULL
|
||||
memory = NULL;
|
||||
}
|
||||
```
|
||||
|
||||
而在Java中,这种操作实际上是不允许的,Java只支持直接使用基本数据类型和对象类型,至于内存到底如何分配,并不是由我们来处理,而是JVM帮助我们进行控制,这样就帮助我们节省很多内存上的工作,虽然带来了很大的便利,但是,一旦出现内存问题,我们就无法像C/C++那样对所管理的内存进行合理地处理,因为所有的内存操作都是由JVM在进行,**只有了解了JVM的内存管理机制,我们才能够在出现内存相关问题时找到解决方案。**
|
||||
|
||||
## 内存管理划分
|
||||
|
||||
既然要管理内存,那么肯定不会是杂乱无章的,JVM对内存的管理采用的是分区治理,不同的内存区域有着各自的职责所在,在虚拟机运行时,内存区域如下划分:
|
||||
|
||||
我们可以看到,内存区域一共分为5个区域,其中方法区和堆是所有线程共享的区域,随着虚拟机的创建而创建,虚拟机的结束而销毁,而虚拟机栈、本地方法栈、程序计数器都是线程之间相互隔离的,每个线程都有一个自己的区域,并且线程启动时会自动创建,结束之后会自动销毁。内存划分完成之后,我们的JVM执行引擎和本地库接口,也就是Java程序开始运行之后就会根据分区合理地使用对应区域的内存了。
|
||||
|
||||
> 大致划分 详情🔗:[https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.5](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.5)
|
||||
|
||||
### 程序计数器
|
||||
|
||||
- **目的**:首先我们来介绍一下程序计数器,它和我们的传统8086 CPU中PC寄存器的工作差不多,因为JVM虚拟机目的就是==**实现物理机那样的程序执行**==。在8086 CPU中,PC作为程序计数器,负责储存内存地址,该地址指向下一条即将执行的指令,每解释执行完一条指令,PC寄存器的值就会自动被更新为下一条指令的地址,进入下一个指令周期时,就会根据当前地址所指向的指令,进行执行。
|
||||
- **作用**:而JVM中的程序计数器可以看做是==**当前线程所执行字节码的行号指示器(记录行号)**==,而行号正好就指的是某一条指令,字节码解释器在工作时也会改变这个值,来指定下一条即将执行的指令,程序计数器因为只需要记录很少的信息,所以只占用很少一部分内存。
|
||||
- 因为Java的多线程也是依靠时间片轮转算法进行的,因此一个CPU同一时间也只会处理一个线程,当某个线程的时间片消耗完成后,会自动切换到下一个线程继续执行,而==**当前线程的执行位置会被保存到当前线程的程序计数器**==中,当下次轮转到此线程时,又继续根据之前的执行位置继续向下执行。
|
||||
|
||||
### 虚拟机栈
|
||||
|
||||
- 虚拟机栈就是一个非常关键的部分,看名字就知道它是一个**栈结构**,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(其实就是栈里面的一个元素:**方法栈帧**),栈帧中包括了当前方法的一些信息,比如局部变量表、操作数栈、动态链接、方法出口等。
|
||||
|
||||

|
||||
|
||||
- 其中局部变量表就是我们方法中的局部变量,之前我们也进行过演示,实际上局部变量表在class文件中就已经定义好了,操作数栈就是我们之前字节码执行时使用到的栈结构; 每个栈帧还保存了一个**可以指向当前方法所在类**的运行时常量池,目的是:当前方法中如果需要调用其他方法的时候,能够从运行时常量池中找到对应的符号引用,然后将符号引用转换为直接引用,然后就能直接调用对应方法,这就是动态链接(我们还没讲到常量池,暂时记住即可,建议之后再回顾一下),最后是方法出口,也就是方法该如何结束,是抛出异常还是正常返回。
|
||||
- 这里我们来模拟一下整个虚拟机栈的运作流程,我们先编写一个测试类:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
int res = a();
|
||||
System.out.println(res);
|
||||
}
|
||||
|
||||
public static int a(){
|
||||
return b();
|
||||
}
|
||||
|
||||
public static int b(){
|
||||
return c();
|
||||
}
|
||||
|
||||
public static int c(){
|
||||
int a = 10;
|
||||
int b = 20;
|
||||
return a + b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
当我们的主方法执行后,会依次执行三个方法`a() -> b() -> c() -> 返回`,我们首先来观察一下反编译之后的结果:
|
||||
|
||||
```Plain
|
||||
{
|
||||
public com.test.Main(); \#这个是构造方法
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=1, args_size=1
|
||||
0: aload_0
|
||||
1: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
4: return
|
||||
LineNumberTable:
|
||||
line 3: 0
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 5 0 this Lcom/test/Main;
|
||||
|
||||
public static void main(java.lang.String[]); \#主方法
|
||||
descriptor: ([Ljava/lang/String;)V
|
||||
flags: ACC_PUBLIC, ACC_STATIC
|
||||
Code:
|
||||
stack=2, locals=2, args_size=1
|
||||
0: invokestatic #2 // Method a:()I
|
||||
3: istore_1
|
||||
4: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
|
||||
7: iload_1
|
||||
8: invokevirtual #4 // Method java/io/PrintStream.println:(I)V
|
||||
11: return
|
||||
LineNumberTable:
|
||||
line 5: 0
|
||||
line 6: 4
|
||||
line 7: 11
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 12 0 args [Ljava/lang/String;
|
||||
4 8 1 res I
|
||||
|
||||
public static int a();
|
||||
descriptor: ()I
|
||||
flags: ACC_PUBLIC, ACC_STATIC
|
||||
Code:
|
||||
stack=1, locals=0, args_size=0
|
||||
0: invokestatic #5 // Method b:()I
|
||||
3: ireturn
|
||||
LineNumberTable:
|
||||
line 10: 0
|
||||
|
||||
public static int b();
|
||||
descriptor: ()I
|
||||
flags: ACC_PUBLIC, ACC_STATIC
|
||||
Code:
|
||||
stack=1, locals=0, args_size=0
|
||||
0: invokestatic #6 // Method c:()I
|
||||
3: ireturn
|
||||
LineNumberTable:
|
||||
line 14: 0
|
||||
|
||||
public static int c();
|
||||
descriptor: ()I
|
||||
flags: ACC_PUBLIC, ACC_STATIC
|
||||
Code:
|
||||
stack=2, locals=2, args_size=0
|
||||
0: bipush 10
|
||||
2: istore_0
|
||||
3: bipush 20
|
||||
5: istore_1
|
||||
6: iload_0
|
||||
7: iload_1
|
||||
8: iadd
|
||||
9: ireturn
|
||||
LineNumberTable:
|
||||
line 18: 0
|
||||
line 19: 3
|
||||
line 20: 6
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
3 7 0 a I
|
||||
6 4 1 b I
|
||||
}
|
||||
```
|
||||
|
||||
可以看到在编译之后,我们整个方法的最大操作数栈深度、局部变量表都是已经确定好的,当我们程序开始执行时,会根据这些信息封装为对应的栈帧,我们从`main`方法开始看起:
|
||||
|
||||

|
||||
|
||||
接着我们继续往下,到了 `0: invokestatic #2 // Method a:()I`时,需要调用方法`a()`,这时当前方法就不会继续向下运行了,而是去执行方法`a()`,那么同样的,将此方法也入栈,注意是放入到栈顶位置,`main`方法的栈帧会被压下去:
|
||||
|
||||

|
||||
|
||||
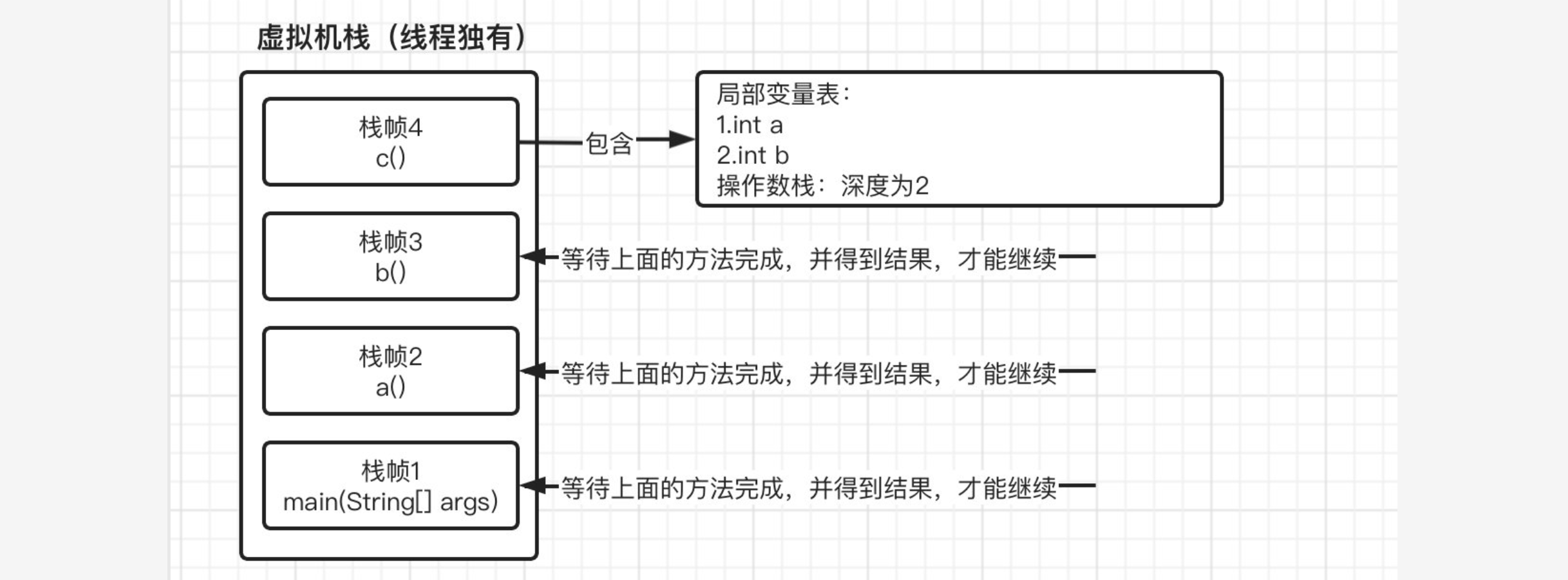
这时,进入方法a之后,又继而进入到方法b,最后在进入c,因此,到达方法c的时候,我们的虚拟机栈变成了:
|
||||
|
||||
|
||||
|
||||
现在我们依次执行方法c中的指令,最后返回a+b的结果,在方法c返回之后,也就代表方法c已经执行结束了,栈帧4会自动出栈,这时栈帧3就得到了上一栈帧返回的结果,并继续执行,但是由于紧接着马上就返回,所以继续重复栈帧4的操作,此时栈帧3也出栈并继续将结果交给下一个栈帧2,最后栈帧2再将结果返回给栈帧1,然后栈帧1就可以继续向下运行了,最后输出结果。
|
||||
|
||||

|
||||
|
||||
### 本地方法栈
|
||||
|
||||
- 本地方法栈与虚拟机栈作用差不多,这里不多做介绍。
|
||||
|
||||
### 堆
|
||||
|
||||
- 堆是整个Java应用程序共享的区域,也是整个虚拟机最大的一块内存空间,而此区域的职责就是**存放和管理对象和数组**,而我们马上要提到的垃圾回收机制也是主要作用于这一部分内存区域。
|
||||
|
||||
### 方法区
|
||||
|
||||
- 方法区也是整个Java应用程序共享的区域,它用于存储所有的类信息、常量、静态变量、动态编译缓存等数据,可以大致分为两个部分,一个是**类信息表**,一个是**运行时常量池**。方法区也是我们要重点介绍的部分。
|
||||
|
||||

|
||||
|
||||
- 首先类信息表中存放的是当前应用程序加载的所有类信息,包括类的版本、字段、方法、接口等信息,同时会将编译时生成的常量池数据全部存放到运行时常量池中。当然,常量也并不是只能从类信息中获取,==在程序运行时,也有可能会有新的常量进入到常量池==。
|
||||
|
||||
- 其实我们的String类正是利用了常量池进行优化,这里我们编写一个测试用例:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
String str1 = new String("abc");
|
||||
String str2 = new String("abc");
|
||||
|
||||
System.out.println(str1 == str2);
|
||||
System.out.println(str1.equals(str2));
|
||||
}
|
||||
```
|
||||
|
||||
得到的结果也是显而易见的,由于`str1`和`str2`是单独创建的两个对象,那么这两个对象实际上会在堆中存放,保存在不同的地址:
|
||||
|
||||

|
||||
|
||||
所以当我们使用`==`判断时,得到的结果`false`,而使用`equals`时因为比较的是值,所以得到`true`。现在我们来稍微修改一下:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
String str1 = "abc";
|
||||
String str2 = "abc";
|
||||
|
||||
System.out.println(str1 == str2);
|
||||
System.out.println(str1.equals(str2));
|
||||
}
|
||||
```
|
||||
|
||||
现在我们没有使用new的形式,而是直接使用双引号创建,那么这时得到的结果就变成了两个`true`,这是为什么呢?这其实是因为我们直接使用双引号赋值,会先在常量池中查找是否存在相同的字符串,若存在,则将引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将引用指向该字符串:
|
||||
|
||||

|
||||
|
||||
实际上两次调用String类的`intern()`方法,和上面的效果差不多,也是第一次调用会将堆中字符串复制并放入常量池中,第二次通过此方法获取字符串时,会查看常量池中是否包含,如果包含那么会直接返回常量池中字符串的地址:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
//不能直接写"abc",双引号的形式,写了就直接在常量池里面吧abc创好了
|
||||
String str1 = new String("ab")+new String("c");
|
||||
String str2 = new String("ab")+new String("c");
|
||||
|
||||
System.out.println(str1.intern() == str2.intern());
|
||||
System.out.println(str1.equals(str2));
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
所以上述结果中得到的依然是两个`true`。在JDK1.7之后,稍微有一些区别,在调用`intern()`方法时,当常量池中没有对应的字符串时,不会再进行复制操作,而是将其直接修改为指向当前字符串堆中的的引用:(也就是说,1.7之前是在字符串常量池中,新建一个String对象保存,1.7之后不创建对象,而是使用引用类型,那么该字符串将一直保存在堆中)
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
//不能直接写"abc",双引号的形式,写了就直接在常量池里面吧abc创好了
|
||||
String str1 = new String("ab")+new String("c");
|
||||
System.out.println(str1.intern() == str1);
|
||||
}
|
||||
```
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
String str1 = new String("ab")+new String("c");
|
||||
String str2 = new String("ab")+new String("c");
|
||||
|
||||
System.out.println(str1 == str1.intern());
|
||||
System.out.println(str2.intern() == str1);
|
||||
}
|
||||
```
|
||||
|
||||
所以最后我们会发现,`str1.intern()`和`str1`都是同一个对象,结果为`true`。
|
||||
|
||||
- 值得注意的是,在JDK7之后,**字符串常量池从方法区移动到了堆中,**也很好理解,毕竟实例已经在堆内存中
|
||||
|
||||
### 总结
|
||||
|
||||
最后我们再来进行一个总结,各个内存区域的用途:
|
||||
|
||||
- (线程独有)程序计数器:保存当前程序的执行位置。
|
||||
- (线程独有)虚拟机栈:通过栈帧来**维持方法调用顺序**,帮助控制程序有序运行。
|
||||
- (线程独有)本地方法栈:同上,作用与本地方法。
|
||||
- 堆:所有的对象和数组都在这里保存。
|
||||
- 方法区:类信息、即时编译器的代码缓存、运行时常量池。
|
||||
|
||||
当然,这些内存区域划分仅仅是概念上的,具体的实现过程我们后面还会提到。
|
||||
|
||||
## 内存泄漏和栈溢出
|
||||
|
||||
- 内存泄漏简单理解,就是==**堆**==**内存不足**,是指当创建过多对象,没有及时进行垃圾回收清空,即存在多个”**泄漏对象**“导致内存不足(`OutOfMemoryError`),称为内存泄漏,数组容量过大也会引起该问题
|
||||
|
||||
- 解决方式:可以通过设置堆内存进行调整:`-Xms最小值 -Xmx最大值`
|
||||
|
||||
- 例子
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
int[] a = new int[Integer.MAX_VALUE];
|
||||
}
|
||||
```
|
||||
|
||||
这里我们申请了一个容量为21亿多的int型数组,显然,如此之大的数组不可能放在我们的堆内存中,所以程序运行时就会这样:
|
||||
|
||||
```Java
|
||||
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit
|
||||
at com.test.Main.main(Main.java:5)
|
||||
```
|
||||
|
||||
这里得到了一个`OutOfMemoryError`错误,也就是我们常说的内存溢出错误。我们可以通过参数来控制堆内存的最大值和最小值:
|
||||
|
||||
```Plain
|
||||
-Xms最小值 -Xmx最大值
|
||||
```
|
||||
|
||||
比如我们现在限制堆内存为固定值1M大小,并且在抛出内存溢出异常时保存当前内存堆转储快照:
|
||||
|
||||

|
||||
|
||||
注意堆内存不要设置太小,不然连虚拟机都不足以启动,
|
||||
|
||||
接着我们编写一个一定会导致内存溢出的程序:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
List<Test> list = new ArrayList<>();
|
||||
while (true){
|
||||
list.add(new Test()); //无限创建Test对象并丢进List中
|
||||
}
|
||||
}
|
||||
|
||||
static class Test{ }
|
||||
}
|
||||
```
|
||||
|
||||
在程序运行之后:
|
||||
|
||||
```Plain
|
||||
java.lang.OutOfMemoryError: Java heap space
|
||||
Dumping heap to java_pid35172.hprof ...
|
||||
Heap dump file created [12895344 bytes in 0.028 secs]
|
||||
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
|
||||
at java.util.Arrays.copyOf(Arrays.java:3210)
|
||||
at java.util.Arrays.copyOf(Arrays.java:3181)
|
||||
at java.util.ArrayList.grow(ArrayList.java:267)
|
||||
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:241)
|
||||
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:233)
|
||||
at java.util.ArrayList.add(ArrayList.java:464)
|
||||
at com.test.Main.main(Main.java:10)
|
||||
```
|
||||
|
||||
可以看到错误出现原因正是`Java heap space`,也就是堆内存满了,并且根据我们设定的VM参数,堆内存保存了快照信息。我们可以在IDEA内置的Profiler中进行查看:
|
||||
|
||||

|
||||
|
||||
可以很明显地看到,在创建了360146个Test对象之后,堆内存蚌埠住了,于是就抛出了内存溢出错
|
||||
|
||||
- **栈溢出**是指栈中的栈帧满了,一般是递归过多或无限递归引发的
|
||||
|
||||
- 解决方式:修改代码逻辑,设置栈内存`-Xss`来设定栈容量
|
||||
|
||||
- 例子
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
test();
|
||||
}
|
||||
|
||||
public static void test(){
|
||||
test();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这很明显是一个永无休止的程序,并且会不断继续向下调用test方法本身,那么按照我们之前的逻辑推导,无限地插入栈帧那么一定会将虚拟机栈塞满,所以,当栈的深度已经不足以继续插入栈帧时,就会这样:
|
||||
|
||||
```Plain
|
||||
Exception in thread "main" java.lang.StackOverflowError
|
||||
at com.test.Main.test(Main.java:12)
|
||||
at com.test.Main.test(Main.java:12)
|
||||
at com.test.Main.test(Main.java:12)
|
||||
at com.test.Main.test(Main.java:12)
|
||||
at com.test.Main.test(Main.java:12)
|
||||
at com.test.Main.test(Main.java:12)
|
||||
....以下省略很多行
|
||||
```
|
||||
|
||||
这也是我们常说的栈溢出,它和堆溢出比较类似,也是由于容纳不下才导致的,我们可以使用`-Xss`来设定栈容量。
|
||||
|
||||
|
||||
|
||||
|
||||
## 申请堆外内存
|
||||
|
||||
- 除了堆内存可以存放对象数据以外,我们也可以申请堆外内存(直接内存),也就是不受JVM管控的内存区域,这部分区域的内存需要我们自行去申请和释放。
|
||||
- 实际上本质就是JVM通过C/C++调用`malloc`函数申请的内存,当然得我们自己去释放了。不过虽然是直接内存,不会受到堆内存容量限制,但是依然会受到本机最大内存的限制,所以还是有可能抛出`OutOfMemoryError`异常。
|
||||
- 这里我们需要提到一个堆外内存操作类:`Unsafe`,就像它的名字一样,虽然Java提供堆外内存的操作类,但是实际上它是不安全的,只有你完全了解底层原理并且能够合理控制堆外内存,才能安全地使用堆外内存(这个类不能直接使用,通过反射获得)
|
||||
|
||||
- 例子
|
||||
|
||||
注意这个类不让我们new,也没有直接获取方式(压根就没想让我们用):
|
||||
|
||||
```Java
|
||||
public final class Unsafe {
|
||||
|
||||
private static native void registerNatives();
|
||||
static {
|
||||
registerNatives();
|
||||
sun.reflect.Reflection.registerMethodsToFilter(Unsafe.class, "getUnsafe");
|
||||
}
|
||||
|
||||
private Unsafe() {}
|
||||
|
||||
private static final Unsafe theUnsafe = new Unsafe();
|
||||
|
||||
@CallerSensitive
|
||||
public static Unsafe getUnsafe() {
|
||||
Class<?> caller = Reflection.getCallerClass();
|
||||
if (!VM.isSystemDomainLoader(caller.getClassLoader()))
|
||||
throw new SecurityException("Unsafe"); //不是JDK的类,不让用。
|
||||
return theUnsafe;
|
||||
}
|
||||
```
|
||||
|
||||
所以我们这里就通过反射给他giao出来:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) throws IllegalAccessException {
|
||||
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
|
||||
unsafeField.setAccessible(true);
|
||||
Unsafe unsafe = (Unsafe) unsafeField.get(null);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
成功拿到Unsafe类之后,我们就可以开始申请堆外内存了,比如我们现在想要申请一个int大小的内存空间,并在此空间中存放一个int类型的数据:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) throws IllegalAccessException {
|
||||
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
|
||||
unsafeField.setAccessible(true);
|
||||
Unsafe unsafe = (Unsafe) unsafeField.get(null);
|
||||
|
||||
//申请4字节大小的内存空间,并得到对应位置的地址
|
||||
long address = unsafe.allocateMemory(4);
|
||||
//在对应的地址上设定int的值
|
||||
unsafe.putInt(address, 6666666);
|
||||
//获取对应地址上的Int型数值
|
||||
System.out.println(unsafe.getInt(address));
|
||||
//释放申请到的内容
|
||||
unsafe.freeMemory(address);
|
||||
|
||||
//由于内存已经释放,这时数据就没了
|
||||
System.out.println(unsafe.getInt(address));
|
||||
}
|
||||
```
|
||||
|
||||
我们可以来看一下`allocateMemory`底层是如何调用的,这是一个native方法,我们来看C++源码:
|
||||
|
||||
```C++
|
||||
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory0(JNIEnv *env, jobject unsafe, jlong size)) {
|
||||
size_t sz = (size_t)size;
|
||||
|
||||
sz = align_up(sz, HeapWordSize);
|
||||
void* x = os::malloc(sz, mtOther); //这里调用了os::malloc方法
|
||||
|
||||
return addr_to_java(x);
|
||||
} UNSAFE_END
|
||||
```
|
||||
|
||||
接着来看:
|
||||
|
||||
```C++
|
||||
void* os::malloc(size_t size, MEMFLAGS flags) {
|
||||
return os::malloc(size, flags, CALLER_PC);
|
||||
}
|
||||
|
||||
void* os::malloc(size_t size, MEMFLAGS memflags, const NativeCallStack& stack) {
|
||||
...
|
||||
u_char* ptr;
|
||||
ptr = (u_char*)::malloc(alloc_size); //调用C++标准库函数 malloc(size)
|
||||
....
|
||||
// we do not track guard memory
|
||||
return MemTracker::record_malloc((address)ptr, size, memflags, stack, level);
|
||||
}
|
||||
```
|
||||
|
||||
所以,我们上面的Java代码转换为C代码,差不多就是这个意思:
|
||||
|
||||
```C
|
||||
\#include <stdlib.h>#include <stdio.h>int main(){
|
||||
int * a = malloc(sizeof(int));
|
||||
*a = 6666666;
|
||||
printf("%d\n", *a);
|
||||
free(a);
|
||||
printf("%d\n", *a);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
- 所以说,直接内存实际上就是JVM申请的一块额外的内存空间,但是它并不在受管控的几种内存空间中,当然这些**内存依然属于是JVM的**,由于JVM提供的堆内存会进行垃圾回收等工作,效率不如直接申请和操作内存来得快,一些比较追求极致性能的框架会用到堆外内存来提升运行速度,如nio框架
|
||||
|
||||
---
|
||||
|
||||
## 垃圾回收机制
|
||||
|
||||
[[垃圾回收机制]]
|
||||
|
||||
## 元空间
|
||||
|
||||
- JDK8之前,Hotspot虚拟机的方法区实际上是永久代实现的。在JDK8之后,Hotspot虚拟机不再使用永久代,而是采用了全新的元空间。类的元信息被存储在元空间中。元空间没有使用堆内存,而是与堆不相连的本地内存区域。所以,理论上系统可以使用的内存有多大,元空间就有多大,所以不会出现永久代存在时的内存溢出问题。这项改造也是有必要的,永久代的调优是很困难的,虽然可以设置永久代的大小,但是很难确定一个合适的大小,因为其中的影响因素很多,比如类数量的多少、常量数量的多少等。
|
||||
|
||||

|
||||
|
||||
因此在JDK8时直接将本地内存作为元空间(**Metaspace**)的区域,物理内存有多大,元空间内存就可以有多大,这样永久代的空间分配问题就讲解了,所以最终它变成了这样:
|
||||
|
||||

|
||||
|
||||
到此,我们对于JVM内存区域的讲解就基本完成了。
|
||||
|
||||
## 引用类型
|
||||
|
||||
### 强引用
|
||||
|
||||
- 我们知道,在Java中,如果变量是一个对象类型的,那么它实际上存放的是对象的引用,但是如果是一个基本类型,那么存放的就是基本类型的值。实际上我们平时代码中类似于`Object o = new Object()`这样的的引用类型,细分之后可以称为`**强引用**`。
|
||||
- 我们通过前面的学习可以明确,如果方法中存在这样的`强引用`类型,现在需要回收强引用所指向的对象,那么要么此==方法运行结束,要么引用连接断开==,否则被引用的对象是无法被判定为可回收的,因为我们说不定后面还要使用它。
|
||||
- 所以,当JVM内存空间不足时,JVM宁愿抛出OutOfMemoryError使程序异常终止,也不会靠随意回收具有强引用的“存活”对象来解决内存不足的问题。
|
||||
|
||||
除了强引用之外,Java也为我们提供了三种额外的引用类型。
|
||||
|
||||
### 软引用
|
||||
|
||||
- 软引用不像强引用那样不可回收,**当 JVM 认为内存不足时**,会去试图回收软引用指向的对象,即JVM 会确保在抛出 `OutOfMemoryError` 之前,清理软引用指向的对象。当然,如果内存充足,那么是不会轻易被回收的。
|
||||
|
||||
- 我们可以通过以下方式来创建一个软引用:使用`**SoftReference**`类
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
//强引用写法:Object obj = new Object();
|
||||
//软引用写法:
|
||||
SoftReference<Object> reference = new SoftReference<>(new Object());
|
||||
//使用get方法就可以获取到软引用所指向的对象了
|
||||
System.out.println(reference.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到软引用还存在一个带队列的构造方法,软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
|
||||
|
||||
这里进行一个测试,首先我们需要设定一下参数,来限制最大堆内存为10M,并且打印GC日志:
|
||||
|
||||
```Plain
|
||||
-XX:+PrintGCDetails -Xms10M -Xmx10M
|
||||
```
|
||||
|
||||
接着运行以下代码:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
ReferenceQueue<Object> queue = new ReferenceQueue<>();
|
||||
SoftReference<Object> reference = new SoftReference<>(new Object(), queue);
|
||||
System.out.println(reference);
|
||||
|
||||
try{
|
||||
List<String> list = new ArrayList<>();
|
||||
while (true) list.add(new String("lbwnb"));
|
||||
}catch (Throwable t){
|
||||
System.out.println("发生了内存溢出!"+t.getMessage());
|
||||
System.out.println("软引用对象:"+reference.get());
|
||||
System.out.println(queue.poll());
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行结果如下:
|
||||
|
||||
```Plain
|
||||
java.lang.ref.SoftReference@232204a1
|
||||
[GC (Allocation Failure) [PSYoungGen: 3943K->501K(4608K)] 3943K->2362K(15872K), 0.0050615 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
|
||||
[GC (Allocation Failure) [PSYoungGen: 3714K->496K(4608K)] 5574K->4829K(15872K), 0.0049642 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
|
||||
[GC (Allocation Failure) [PSYoungGen: 3318K->512K(4608K)] 7652K->7711K(15872K), 0.0059440 secs] [Times: user=0.03 sys=0.00, real=0.00 secs]
|
||||
[GC (Allocation Failure) --[PSYoungGen: 4608K->4608K(4608K)] 11807K->15870K(15872K), 0.0078912 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
|
||||
[Full GC (Ergonomics) [PSYoungGen: 4608K->0K(4608K)] [ParOldGen: 11262K->10104K(11264K)] 15870K->10104K(15872K), [Metaspace: 3207K->3207K(1056768K)], 0.0587856 secs] [Times: user=0.24 sys=0.00, real=0.06 secs]
|
||||
[Full GC (Ergonomics) [PSYoungGen: 4096K->1535K(4608K)] [ParOldGen: 10104K->11242K(11264K)] 14200K->12777K(15872K), [Metaspace: 3207K->3207K(1056768K)], 0.0608198 secs] [Times: user=0.25 sys=0.01, real=0.06 secs]
|
||||
[Full GC (Ergonomics) [PSYoungGen: 3965K->3896K(4608K)] [ParOldGen: 11242K->11242K(11264K)] 15207K->15138K(15872K), [Metaspace: 3207K->3207K(1056768K)], 0.0972088 secs] [Times: user=0.58 sys=0.00, real=0.10 secs]
|
||||
[Full GC (Allocation Failure) [PSYoungGen: 3896K->3896K(4608K)] [ParOldGen: 11242K->11225K(11264K)] 15138K->15121K(15872K), [Metaspace: 3207K->3207K(1056768K)], 0.1028222 secs] [Times: user=0.63 sys=0.01, real=0.10 secs]
|
||||
发生了内存溢出!Java heap space
|
||||
软引用对象:null
|
||||
java.lang.ref.SoftReference@232204a1
|
||||
Heap
|
||||
PSYoungGen total 4608K, used 4048K [0x00000007bfb00000, 0x00000007c0000000, 0x00000007c0000000)
|
||||
eden space 4096K, 98% used [0x00000007bfb00000,0x00000007bfef40a8,0x00000007bff00000)
|
||||
from space 512K, 0% used [0x00000007bff00000,0x00000007bff00000,0x00000007bff80000)
|
||||
to space 512K, 0% used [0x00000007bff80000,0x00000007bff80000,0x00000007c0000000)
|
||||
ParOldGen total 11264K, used 11225K [0x00000007bf000000, 0x00000007bfb00000, 0x00000007bfb00000)
|
||||
object space 11264K, 99% used [0x00000007bf000000,0x00000007bfaf64a8,0x00000007bfb00000)
|
||||
Metaspace used 3216K, capacity 4500K, committed 4864K, reserved 1056768K
|
||||
class space used 352K, capacity 388K, committed 512K, reserved 1048576K
|
||||
```
|
||||
|
||||
可以看到,当内存不足时,软引用所指向的对象被回收了,所以`get()`方法得到的结果为null,并且软引用对象本身被丢进了队列中。
|
||||
|
||||
|
||||
|
||||
|
||||
### 弱引用
|
||||
|
||||
- 弱引用比软引用的生命周期还要短,**在进行垃圾回收时**,不管当前内存空间是否充足,都会回收它的内存。
|
||||
|
||||
- 我们可以像这样创建一个弱引用:使用`**WeakReference**`类
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
WeakReference<Object> reference = new WeakReference<>(new Object());
|
||||
System.out.println(reference.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用方法和软引用是差不多的,但是如果我们在这之前手动进行一次GC:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
SoftReference<Object> softReference = new SoftReference<>(new Object());
|
||||
WeakReference<Object> weakReference = new WeakReference<>(new Object());
|
||||
|
||||
//手动GC
|
||||
System.gc();
|
||||
|
||||
System.out.println("软引用对象:"+softReference.get());
|
||||
System.out.println("弱引用对象:"+weakReference.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,弱引用对象直接就被回收了,而软引用对象没有被回收。同样的,它也支持ReferenceQueue,和软引用用法一致,这里就不多做介绍了。
|
||||
|
||||
`WeakHashMap`正是一种类似于弱引用的HashMap类,如果Map中的Key没有其他引用那么此Map会自动丢弃此键值对。
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Integer a = new Integer(1);
|
||||
|
||||
WeakHashMap<Integer, String> weakHashMap = new WeakHashMap<>();
|
||||
weakHashMap.put(a, "yyds");
|
||||
System.out.println(weakHashMap);
|
||||
|
||||
a = null;
|
||||
System.gc();
|
||||
|
||||
System.out.println(weakHashMap);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,**当变量a的引用断开后**,这时只有WeakHashMap本身对此对象存在引用,所以在GC之后,这个键值对就自动被舍弃了。所以说这玩意,就挺适合拿去做缓存的。
|
||||
|
||||
|
||||
|
||||
|
||||
### 虚引用(鬼引用)
|
||||
|
||||
- 虚引用相当于没有引用,随时都有可能会被回收。
|
||||
|
||||
- 看看它的源码,非常简单:`**PhantomReference**`
|
||||
|
||||
```Java
|
||||
public class PhantomReference<T> extends Reference<T> {
|
||||
|
||||
/**
|
||||
* Returns this reference object's referent. Because the referent of a
|
||||
* phantom reference is always inaccessible, this method always returns
|
||||
* <code>null</code>.
|
||||
*
|
||||
* @return <code>null</code>
|
||||
*/
|
||||
public T get() {
|
||||
return null;
|
||||
}
|
||||
|
||||
/**
|
||||
* Creates a new phantom reference that refers to the given object and
|
||||
* is registered with the given queue.
|
||||
*
|
||||
* <p> It is possible to create a phantom reference with a <tt>null</tt>
|
||||
* queue, but such a reference is completely useless: Its <tt>get</tt>
|
||||
* method will always return null and, since it does not have a queue, it
|
||||
* will never be enqueued.
|
||||
*
|
||||
* @param referent the object the new phantom reference will refer to
|
||||
* @param q the queue with which the reference is to be registered,
|
||||
* or <tt>null</tt> if registration is not required
|
||||
*/
|
||||
public PhantomReference(T referent, ReferenceQueue<? super T> q) {
|
||||
super(referent, q);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
也就是说我们无论调用多少次`get()`方法得到的永远都是`null`,因为虚引用本身就不算是个引用,相当于这个对象不存在任何引用,并且只能使用带队列的构造方法,以便对象被回收时接到通知
|
||||
|
||||
|
||||
最后,Java中4种引用的级别由高到低依次为: **强引用 > 软引用 > 弱引用 > 虚引用**
|
||||
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
{kind=link}
|
After Width: | Height: | Size: 111 KiB |
{kind=link}
|
After Width: | Height: | Size: 137 KiB |
{kind=link}
|
After Width: | Height: | Size: 395 KiB |
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
{kind=link}
|
After Width: | Height: | Size: 117 KiB |
{kind=link}
|
After Width: | Height: | Size: 191 KiB |
{kind=link}
|
After Width: | Height: | Size: 100 KiB |
{kind=link}
|
After Width: | Height: | Size: 197 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.0 MiB |
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
{kind=link}
|
After Width: | Height: | Size: 489 KiB |
{kind=link}
|
After Width: | Height: | Size: 550 KiB |
{kind=link}
|
After Width: | Height: | Size: 160 KiB |
{kind=link}
|
After Width: | Height: | Size: 112 KiB |
@@ -0,0 +1,154 @@
|
||||
---
|
||||
title: JVM前篇
|
||||
date: 2024-08-25
|
||||
tags: [JVM]
|
||||
---
|
||||
|
||||
|
||||
## 前言
|
||||
|
||||
jvm规范
|
||||
|
||||

|
||||
|
||||
## 概述
|
||||
|
||||
首先我们要了解虚拟机的具体定义,我们所接触过的虚拟机有安装操作系统的虚拟机,也有我们的Java虚拟机,而它们所面向的对象不同,Java虚拟机只是面向单一应用程序的虚拟机,但是它和我们接触的系统级虚拟机一样,我们也可以为其分配实际的硬件资源,比如最大内存大小等。
|
||||
|
||||
|
||||
|
||||
并且Java虚拟机并没有采用传统的PC架构,比如现在的**HotSpot虚拟机**,实际上采用的是`**基于栈的指令集架构**`,而我们的传统程序设计一般都是`基于``**寄存器**``的指令集架构`,这里我们需要回顾一下`计算机组成原理`中的CPU结构:
|
||||
|
||||

|
||||
|
||||
> 省略了C语言在不同架构下编译出的汇编程序
|
||||
|
||||
C语言在不同的CPU架构下,实际上得到的汇编代码也不一样,并且在arm架构下并没有和x86架构一样的寄存器结构,因此只能使用不同的汇编指令操作来实现。所以这也是为什么C语言不支持跨平台的原因,依赖于硬件的支持。
|
||||
|
||||
Java利用了JVM,它提供了很好的平台无关性(当然,JVM本身是不跨平台的),我们的Java程序编译之后,并不是可以由平台直接运行的程序,而是由JVM运行,同时,我们前面说了,JVM(如HotSpot虚拟机),实际上采用的是`基于栈的指令集架构`,它并没有依赖于寄存器,而是更多的利用操作栈来完成,这样不仅设计和实现起来更简单,并且也能够更加方便地实现跨平台,不太依赖于硬件的支持。
|
||||
|
||||
> 省略分析字节码(class)文件分析
|
||||
|
||||
实际上我们发现,JVM执行的命令基本都是**入栈出栈**等,而且大部分指令都是没有==操作数(字面量)==的,传统的汇编指令有一操作数、二操作数甚至三操作数的指令,Java相比C编译出来的汇编指令,执行起来会更加复杂,实现某个功能的指令条数也会更多,所以Java的执行效率实际上是不如C/C++的,虽然能够很方便地实现跨平台,但是性能上大打折扣,所以在性能要求比较苛刻的Android上,采用的是**定制版的JVM**,并且是==基于寄存器的指令集架构==。此外,在某些情况下,我们还可以使用JNI机制来通过Java调用C/C++编写的程序以提升性能(也就是本地方法,使用到native关键字)
|
||||
|
||||
## jvm历史
|
||||
|
||||
JVM会根据当前代码的进行判断,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler)
|
||||
|
||||

|
||||
|
||||
## JVM启动流程
|
||||
|
||||

|
||||
|
||||
## JNI调用本地方法
|
||||
|
||||
Java还有一个**JNI**机制,它的全称:==Java Native Interface==,即Java本地接口。它允许在Java虚拟机内运行的Java代码与其他编程语言(如C/C++和汇编语言)编写的程序和库进行交互(在Android开发中用得比较多)比如我们现在想要让C语言程序帮助我们的Java程序实现a+b的运算,首先我们需要创建一个本地方法:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
System.out.println(sum(1, 2));
|
||||
}
|
||||
//本地方法使用native关键字标记,无需任何实现,交给C语言实现
|
||||
public static native int sum(int a, int b);
|
||||
}
|
||||
```
|
||||
|
||||
创建好后,接着点击构建(编译)按钮,会出现一个out文件夹,也就是生成的class文件在其中,接着我们直接生成对应的C头文件:
|
||||
|
||||
```Shell
|
||||
javah -classpath out/production/SimpleHelloWorld -d ./jni com.test.Main
|
||||
```
|
||||
|
||||
生成的头文件位于jni文件夹下:
|
||||
|
||||
```C
|
||||
/* DO NOT EDIT THIS FILE - it is machine generated */
|
||||
\#include <jni.h>/* Header for class com_test_Main */
|
||||
|
||||
\#ifndef _Included_com_test_Main
|
||||
\#define _Included_com_test_Main
|
||||
\#ifdef __cplusplus
|
||||
extern "C" {
|
||||
\#endif/*
|
||||
* Class: com_test_Main
|
||||
* Method: sum
|
||||
* Signature: (II)V
|
||||
*/
|
||||
JNIEXPORT void JNICALL Java_com_test_Main_sum
|
||||
(JNIEnv *, jclass, jint, jint);
|
||||
|
||||
\#ifdef __cplusplus
|
||||
}
|
||||
\#endif#endif
|
||||
```
|
||||
|
||||
接着我们在CLion中新建一个C++项目,并引入刚刚生成的头文件,并导入jni相关头文件(在JDK文件夹中)首先修改CMake文件:
|
||||
|
||||
```Plain
|
||||
cmake_minimum_required(VERSION 3.21)
|
||||
project(JNITest)
|
||||
|
||||
include_directories(/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/include)
|
||||
include_directories(/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/include/darwin)
|
||||
set(CMAKE_CXX_STANDARD 14)
|
||||
|
||||
add_executable(JNITest com_test_Main.cpp com_test_Main.h)
|
||||
```
|
||||
|
||||
接着就可以编写实现了,首先认识一下引用类型对照表:
|
||||
|
||||

|
||||
|
||||
所以我们这里直接返回a+b即可:
|
||||
|
||||
```C++
|
||||
\#include "com_test_Main.h"JNIEXPORT jint JNICALL Java_com_test_Main_sum
|
||||
(JNIEnv * env, jclass clazz, jint a, jint b){
|
||||
return a + b;
|
||||
}
|
||||
```
|
||||
|
||||
接着我们就可以将cpp编译为动态链接库,在MacOS下会生成`.dylib`文件,Windows下会生成`.dll`文件,我们这里就只以MacOS为例,命令有点长,因为还需要包含JDK目录下的头文件:
|
||||
|
||||
```Shell
|
||||
gcc com_test_Main.cpp -I /Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/include -I /Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/include/darwin -fPIC -shared -o test.dylib -lstdc++
|
||||
```
|
||||
|
||||
编译完成后,得到`test.dylib`文件,这就是动态链接库了。
|
||||
|
||||
最后我们再将其放到桌面,然后在Java程序中加载:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
static {
|
||||
System.load("/Users/nagocoler/Desktop/test.dylib");
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
System.out.println(sum(1, 2));
|
||||
}
|
||||
|
||||
public static native int sum(int a, int b);
|
||||
}
|
||||
```
|
||||
|
||||
运行,成功得到结果:
|
||||
|
||||
```shell
|
||||
/home/nagocoler/jdk-jdk8-b120/build/linux-x86_64-normal-server-slowdebug/jdk/bin/java Main
|
||||
Hello World!
|
||||
|
||||
Process finished with exit code 0
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
- 在Java中编写方法接口(即native修饰的方法)
|
||||
- 编译生成class文件,根据clas文件生成JNI头文件(C头文件),其中包含你在C代码中需要实现的函数声明(生成一个c头文件,头文件说明了需要的函数)
|
||||
- 创建C项目,引入生成的头文件,编写需要实现的函数
|
||||
- 使用==CMake==将C编译成动态链接共享库
|
||||
- 运行Java程序(需要调用系统类对共享库进行加载)
|
||||
|
||||
通过了解JVM的一些基础知识,我们心目中大致有了一个JVM的模型,在下一章,我们将继续深入学习JVM的内存管理机制和垃圾收集器机制,以及一些实用工具。
|
||||
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
{kind=link}
|
After Width: | Height: | Size: 689 KiB |
{kind=link}
|
After Width: | Height: | Size: 410 KiB |
{kind=link}
|
After Width: | Height: | Size: 361 KiB |
@@ -0,0 +1,837 @@
|
||||
---
|
||||
title: JVM后篇
|
||||
date: 2024-08-25
|
||||
tags: [JVM]
|
||||
---
|
||||
|
||||
|
||||
# 类与类加载
|
||||
|
||||
## 类文件结构
|
||||
|
||||
- 概述
|
||||
|
||||
在我们学习C语言的时候,我们的编程过程会经历如下几个阶段:写代码、保存、编译、运行。实际上,最关键的一步是**编译**,因为只有经历了编译之后,我们所编写的代码才能够翻译为机器可以直接运行的二进制代码,并且在不同的操作系统下,我们的代码都需要进行一次编译之后才能运行。
|
||||
|
||||
> 如果全世界所有的计算机指令集只有x86一种,操作系统只有Windows一种,那也许就不会有Java语言的出现。
|
||||
|
||||
随着时代的发展,人们迫切希望能够在不同的操作系统、不同的计算机架构中运行同一套编译之后的代码。本地代码不应该是我们编程的唯一选择,所以,越来越多的语言选择了与操作系统和机器指令集无关的中立格式作为编译后的存储格式。
|
||||
|
||||
“一次编写,到处运行”,Java最引以为傲的口号,标志着平台不再是限制编程语言的阻碍。
|
||||
|
||||
实际上,Java正式利用了这样的解决方案,将源代码编译为平台无关的中间格式,并通过对应的Java虚拟机读取和运行这些中间格式的编译文件,这样,我们只需要考虑不同平台的虚拟机如何编写,而Java语言本身很轻松地实现了跨平台。
|
||||
|
||||
|
||||
现在,越来越多的开发语言都支持将源代码编译为`.class`字节码文件格式,以便能够直接交给JVM运行,包括Kotlin(安卓开发官方指定语言)、Groovy、Scala等。
|
||||
|
||||

|
||||
|
||||
那么,让我们来看看,我们的源代码编译之后,是如何保存在字节码文件中的。
|
||||
|
||||
---
|
||||
|
||||
### 类文件信息
|
||||
|
||||
- 查看class文件,进行解析
|
||||
|
||||
我们之前都是使用`javap`命令来对字节码文件进行反编译查看的,那么,它以二进制格式是怎么保存呢?我们可以使用WinHex软件(Mac平台可以使用[010 Editor](https://www.macwk.com/soft/010-editor))来以十六进制查看字节码文件。
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
int i = 10;
|
||||
int a = i++;
|
||||
int b = ++i;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
找到我们在IDEA中编译出来的class文件,将其拖动进去:
|
||||
|
||||

|
||||
|
||||
可以看到整个文件中,全是一个字节一个字节分组的样子,从左上角开始,一行一行向下读取。可以看到在右侧中还出现了一些我们之前也许见过的字符串,比如"<init>"、"Object"等。
|
||||
|
||||
实际上Class文件采用了一种类似于C中结构体的伪结构来存储数据(当然我们直接看是看不出来的),但是如果像这样呢?
|
||||
|
||||
```Plain
|
||||
Classfile /Users/nagocoler/Develop.localized/JavaHelloWorld/target/classes/com/test/Main.class
|
||||
Last modified 2022-2-23; size 444 bytes
|
||||
MD5 checksum 8af3e63f57bcb5e3d0eec4b0468de35b
|
||||
Compiled from "Main.java"
|
||||
public class com.test.Main
|
||||
minor version: 0
|
||||
major version: 52
|
||||
flags: ACC_PUBLIC, ACC_SUPER
|
||||
Constant pool:
|
||||
#1 = Methodref #3.#21 // java/lang/Object."<init>":()V
|
||||
#2 = Class #22 // com/test/Main
|
||||
#3 = Class #23 // java/lang/Object
|
||||
#4 = Utf8 <init>
|
||||
#5 = Utf8 ()V
|
||||
#6 = Utf8 Code
|
||||
#7 = Utf8 LineNumberTable
|
||||
#8 = Utf8 LocalVariableTable
|
||||
#9 = Utf8 this
|
||||
#10 = Utf8 Lcom/test/Main;
|
||||
#11 = Utf8 main
|
||||
#12 = Utf8 ([Ljava/lang/String;)V
|
||||
#13 = Utf8 args
|
||||
#14 = Utf8 [Ljava/lang/String;
|
||||
#15 = Utf8 i
|
||||
#16 = Utf8 I
|
||||
#17 = Utf8 a
|
||||
#18 = Utf8 b
|
||||
#19 = Utf8 SourceFile
|
||||
#20 = Utf8 Main.java
|
||||
#21 = NameAndType #4:#5 // "<init>":()V
|
||||
#22 = Utf8 com/test/Main
|
||||
#23 = Utf8 java/lang/Object
|
||||
{
|
||||
public com.test.Main();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=1, args_size=1
|
||||
0: aload_0
|
||||
1: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
4: return
|
||||
LineNumberTable:
|
||||
line 11: 0
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 5 0 this Lcom/test/Main;
|
||||
|
||||
public static void main(java.lang.String[]);
|
||||
descriptor: ([Ljava/lang/String;)V
|
||||
flags: ACC_PUBLIC, ACC_STATIC
|
||||
Code:
|
||||
stack=1, locals=4, args_size=1
|
||||
0: bipush 10
|
||||
2: istore_1
|
||||
3: iload_1
|
||||
4: iinc 1, 1
|
||||
7: istore_2
|
||||
8: iinc 1, 1
|
||||
11: iload_1
|
||||
12: istore_3
|
||||
13: return
|
||||
LineNumberTable:
|
||||
line 13: 0
|
||||
line 14: 3
|
||||
line 15: 8
|
||||
line 16: 13
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 14 0 args [Ljava/lang/String;
|
||||
3 11 1 i I
|
||||
8 6 2 a I
|
||||
13 1 3 b I
|
||||
}
|
||||
SourceFile: "Main.java"
|
||||
```
|
||||
|
||||
乍一看,是不是感觉还真的有点结构体那味?
|
||||
|
||||
而结构体中,有两种允许存在的数据类型,一个是无符号数,还有一个是表。
|
||||
|
||||
- 无符号数一般是基本数据类型,==用u1、u2、u4、u8来表示,表示1个字节~8个字节的无符号数==。可以表示数字、索引引用、数量值或是以UTF-8编码格式的字符串。
|
||||
- 表包含多个无符号数,并且以"_info"结尾。
|
||||
|
||||
我们首先从最简的开始看起。
|
||||
|
||||

|
||||
|
||||
- 首先,我们可以看到,==前4个字节(共32位)组成了魔数==(其实就是表示这个文件是一个JVM可以运行的字节码文件,除了Java以外,其他某些文件中也采用了这种魔数机制来进行区分,这种方式比直接起个文件扩展名更安全)
|
||||
- 字节码文件的魔数为:==**CAFEBABE**==(这名字能想出来也是挺难的了,毕竟4个bit位只能表示出A-F这几个字母)
|
||||
- 紧接着魔数的==后面4个字节存储的是字节码文件的版本号==,注意前两个是次要版本号(现在基本都不用了,都是直接Java8、Java9这样命名了),后面两个是主要版本号,这里我们主要看主版本号,比如上面的就是34,注意这是以16进制表示的,我们把它换算为10进制后,得到的结果为:`34 -> 3*16 + 4 = 52`,其中`52`代表的是`JDK8`编译的字节码文件(51是JDK7、50是JDK6、53是JDK9,以此类推)
|
||||
- JVM会根据版本号决定是否能够运行,比如JDK6只能支持版本号为1.1~6的版本,也就是说必须是Java6之前的环境编译出来的字节码文件,否则无法运行。又比如我们现在安装的是JDK8版本,它能够支持的版本号为1.1~8,那么如果这时我们有一个通过Java7编译出来的字节码文件,依然是可以运行的,所以说Java版本是向下兼容的。
|
||||
- 紧接着,就是类的常量池了,这里面存放了类中所有的常量信息(注意这里的常量并不是指我们手动创建的final类型常量,而是程序运行一些需要用到的常量数据,比如==字面量和符号引用等==)由于常量的数量不是确定的,所以在最开始的位置会存放常量池中常量的数量(是从1开始计算的,不是0,比如这里是18,翻译为10进制就是24,所以实际上有23个常量)
|
||||
|
||||
接着再往下,就是常量池里面的数据了,每一项常量池里面的数据都是一个表,我们可以看到他们都是以_info结尾的:
|
||||
|
||||

|
||||
|
||||
我们来看看一个表中定义了哪些内容:
|
||||
|
||||

|
||||
|
||||
首先上来就会有一个1字节的无符号数,它用于表示当前常量的类型(常量类型有很多个)这里只列举一部分的类型介绍:
|
||||
|
||||
| | | |
|
||||
|---|---|---|
|
||||
|类型|标志|描述|
|
||||
|CONSTANT_Utf8_info|1|UTF-8编码格式的字符串|
|
||||
|CONSTANT_Integer_info|3|整形字面量(第一章我们演示的很大的数字,实际上就是以字面量存储在常量池中的)|
|
||||
|CONSTANT_Class_info|7|类或接口的符号引用|
|
||||
|CONSTANT_String_info|8|字符串类型的字面量|
|
||||
|CONSTANT_Fieldref_info|9|字段的符号引用|
|
||||
|CONSTANT_Methodref_info|10|方法的符号引用|
|
||||
|CONSTANT_MethodType_info|16|方法类型|
|
||||
|CONSTANT_NameAndType_info|12|字段或方法的部分符号引用|
|
||||
|
||||
实际上这些东西,虽然我们不知道符号引用是什么东西,我们可以观察出来,这些东西或多或少都是存放类中一些名称、数据之类的东西。
|
||||
|
||||
比如我们来看第一个`CONSTANT_Methodref_info`表中存放了什么数据,这里我只列出它的结构表(详细的结构表可以查阅《深入理解Java虚拟机 第三版》中222页总表):
|
||||
|
||||
| | | | |
|
||||
|---|---|---|---|
|
||||
|常量|项目|类型|描述|
|
||||
|CONSTANT_Methodref_info|tag|u1|值为10|
|
||||
||index|u2|指向声明方法的类描述父CONSTANT_Class_info索引项|
|
||||
||index|u2|指向名称及类型描述符CONSTANT_NameAndType_info索引项|
|
||||
|
||||
比如我们刚刚的例子中:
|
||||
|
||||

|
||||
|
||||
可以看到,第一个索引项指向了第3号常量,我们来看看三号常量:
|
||||
|
||||

|
||||
|
||||
| 常量 | 项目 | 类型 | 描述 |
|
||||
| ------------------- | ----- | ---- | ------------------------ |
|
||||
| CONSTANT_Class_info | tag | u1 | 值为7 |
|
||||
| | index | u2 | 指向全限定名常量项的索引 |
|
||||
|
||||
那么我们接着来看23号常量又写的啥:
|
||||
|
||||

|
||||
|
||||
可以看到指向的UTF-8字符串值为`java/lang/Object`这下搞明白了,首先这个方法是由Object类定义的,那么接着我们来看第二项u2 `name_and_type_index`,指向了21号常量,也就是字段或方法的部分符号引用:
|
||||
|
||||

|
||||
|
||||
|常量|项目|类型|描述|
|
||||
|---|---|---|---|
|
||||
|CONSTANT_NameAndType_info|tag|u1|值为12|
|
||||
||index|u2|指向字段或方法名称常量项的索引|
|
||||
||index|u2|指向字段或方法描述符常量项的索引|
|
||||
|
||||
其中第一个索引就是方法的名称,而第二个就是方法的描述符,描述符明确了方法的参数以及返回值类型,我们分别来看看4号和5号常量:
|
||||
|
||||

|
||||
|
||||
可以看到,方法名称为"<init>",一般构造方法的名称都是<init>,普通方法名称是什么就是什么,方法描述符为"()V",表示此方法没有任何参数,并且返回值类型为void,描述符对照表如下:
|
||||
|
||||

|
||||
|
||||
比如这里有一个方法`public int test(double a, char c){ ... }`,那么它的描述符就应该是:`(DC)I`,参数依次放入括号中,括号右边是返回值类型。再比如`public String test(Object obj){ ... }`,那么它的描述符就应该是:`(Ljava/lang/Object;)Ljava/lang/String`,注意如果参数是对象类型,那么必须在后面添加`;`
|
||||
|
||||
对于数组类型,只需要在类型最前面加上`[`即可,有几个维度,就加几个,比如`public void test(int[][] arr)`,参数是一个二维int类型数组,那么它的描述符为:`([[I)V`
|
||||
|
||||
所以,这里表示的,实际上就是此方法是一个无参构造方法,并且是属于Object类的。那么,为什么这里需要Object类构造方法的符号引用呢?还记得我们在JavaSE中说到的,每个类都是直接或间接继承自Object类,所有类的构造方法,必须先调用父类的构造方法,但是如果父类存在无参构造,默认可以不用显示调用`super`关键字(当然本质上是调用了的)。
|
||||
|
||||
所以说,当前类因为没有继承自任何其他类,那么就默认继承的Object类,所以,在当前类的默认构造方法中,调用了父类Object类的无参构造方法,因此这里需要符号引用的用途显而易见,就是因为需要调用Object类的无参构造方法。
|
||||
|
||||
我们可以在反编译结果中的方法中看到:
|
||||
|
||||
```Plain
|
||||
public com.test.Main();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=1, args_size=1
|
||||
0: aload_0
|
||||
1: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
4: return
|
||||
LineNumberTable:
|
||||
line 11: 0
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 5 0 this Lcom/test/Main;
|
||||
```
|
||||
|
||||
其中`invokespecial`(调用父类构造方法)指令的参数指向了1号常量,而1号常量正是代表的Object类的无参构造方法,虽然饶了这么大一圈,但是过程理清楚,还是很简单的。
|
||||
|
||||
虽然我们可以直接查看16进制的结果,但是还是不够方便,但是我们也不能每次都去使用`javap`命令,所以我们这里安装一个IDEA插件,来方便我们查看字节码中的信息,名称为`jclasslib Bytecode Viewer` :
|
||||
|
||||

|
||||
|
||||
安装完成后,我们可以在我们的IDEA右侧看到它的板块,但是还没任何数据,那么比如现在我们想要查看Main类的字节码文件时,可以这样操作:
|
||||
|
||||

|
||||
|
||||
首先在项目中选中我们的Main类,然后点击工具栏的视图,然后点击`Show Bytecode With Jclasslib`,这样右侧就会出现当前类的字节码解析信息了。注意如果修改了类的话,那么需要你点击运行或是构建,然后点击刷新按钮来进行更新。
|
||||
|
||||
接着我们来看下一个内容,在常量池之后,紧接着就是访问标志,访问标志就是类的种类以及类上添加的一些关键字等内容:
|
||||
|
||||

|
||||
|
||||
可以看到它只占了2个字节,那么它是如何表示访问标志呢?
|
||||
|
||||

|
||||
|
||||
比如我们这里的Main类,它是一个普通的class类型,并且访问权限为public,那么它的访问标志值是这样计算的:
|
||||
|
||||
`ACC_PUBLIC | ACC_SUPER = 0x0001 | 0x0020 = 0x0021`(这里进行的是按位或运算),可以看到和我们上面的结果是一致的。
|
||||
|
||||
再往下就是类索引、父类索引、接口索引:
|
||||
|
||||

|
||||
|
||||
可以看到它们的值也是指向常量池中的值,其中2号常量正是存储的当前类信息,3号常量存储的是父类信息,这里就不再倒推回去了,由于没有接口,所以这里接口数量为0,如果不为0还会有一个索引表来引用接口。
|
||||
|
||||
接着就是字段和方法表集合了:
|
||||
|
||||

|
||||
|
||||
由于我们这里没有声明任何字段,所以我们先给Main类添加一个字段再重新加载一下:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
|
||||
public static int a = 10;
|
||||
|
||||
public static void main(String[] args) {
|
||||
int i = 10;
|
||||
int a = i++;
|
||||
int b = ++i;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
现在字节码就新增了一个字段表,这个字段表实际上就是我们刚刚添加的成员字段`a`的数据。
|
||||
|
||||
可以看到一共有四个2字节的数据:
|
||||
|
||||

|
||||
|
||||
首先是`access_flags`,这个与上面类标志的计算规则是一样的,表还是先列出来吧:
|
||||
|
||||

|
||||
|
||||
第二个数据`name_index`表示字段的名称常量,这里指向的是5号常量,那么我们来看看5号常量是不是字段名称:
|
||||
|
||||

|
||||
|
||||
没问题,这里就是`a`,下一个是`descirptor_index`,存放的是描述符,不过这里因为不是方法而是变量,所以描述符直接写对应类型的标识字符即可,比如这里是`int`类型,那么就是`I`。
|
||||
|
||||
最后,`attrbutes_count`属性计数器,用于描述一些额外信息,这里我们暂时不做介绍。
|
||||
|
||||
接着就是我们的方法表了:
|
||||
|
||||

|
||||
|
||||
可以看到方法表中一共有三个方法,其中第一个方法我们刚刚已经介绍过了,它的方法名称为`<init>`,表示它是一个构造方法,我们看到最后一个方法名称为`<clinit>`,这个是类在初始化时会调用的方法(是隐式的,自动生成的),它主要是用于静态变量初始化语句和静态块的执行,因为我们这里给静态成员变量a赋值为10,所以会在一开始为其赋值:
|
||||
|
||||

|
||||
|
||||
而第二个方法,就是我们的`main`方法了,但是现在我们先不急着去看它的详细实现过程,我们来看看它的属性表。
|
||||
|
||||
属性表实际上类中、字段中、方法中都可以携带自己的属性表,属性表存放的正是我们的代码、本地变量等数据,比如main方法就存在4个本地变量,那么它的本地变量存放在哪里呢:
|
||||
|
||||

|
||||
|
||||
可以看到,属性信息呈现套娃状态,在此方法中的属性包括了一个Code属性,此属性正是我们的Java代码编译之后变成字节码指令,然后存放的地方,而在此属性中,又嵌套了本地变量表和源码行号表。
|
||||
|
||||
可以看到code中存放的就是所有的字节码指令:
|
||||
|
||||

|
||||
|
||||
这里我们暂时不对字节码指令进行讲解(其实也用不着讲了,都认识的差不多了)。我们接着来看本地变量表,这里存放了我们方法中要用到的局部变量:
|
||||
|
||||

|
||||
|
||||
可以看到一共有四个本地变量,而第一个变量正是main方法的形参`String[] args`,并且表中存放了本地变量的长度、名称、描述符等内容。当然,除了我们刚刚认识的这几个属性之外,完整属性可以查阅《深入理解Java虚拟机 第三版》231页。
|
||||
|
||||
最后,类也有一些属性:
|
||||
|
||||

|
||||
|
||||
此属性记录的是源文件名称。
|
||||
|
||||
这样,我们对一个字节码文件的认识差不多就结束了,在了解了字节码文件的结构之后,是不是感觉豁然开朗?
|
||||
|
||||
|
||||
|
||||
|
||||
### 字节码指令
|
||||
|
||||
- 查看class文件,分析指令
|
||||
|
||||
- 虚拟机的指令是由一个字节长度的、代表某种特定操作含义的数字(操作码,类似于机器语言),操作后面也可以携带0个或多个参数一起执行。我们前面已经介绍过了,JVM实际上并不是面向寄存器架构的,而是面向操作数栈,所以大多数指令都是不带参数的。
|
||||
|
||||
由于之前已经讲解过大致运行流程,这里我们就以当前的Main类中的main方法作为教材进行讲解:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
int i = 10;
|
||||
int a = i++;
|
||||
int b = ++i;
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,main方法中首先是定义了一个int类型的变量i,并赋值为10,然后变量a接收`i++`的值,变量b接收`++i`的值。
|
||||
|
||||
那么我们来看看编译成字节码之后,是什么样的:
|
||||
|
||||

|
||||
|
||||
- 首先第一句,`bipush`,将10送至操作数栈顶。
|
||||
- 接下来将操作数栈顶的数值存进1号本地变量,也就是变量i中。
|
||||
- 接着将变量i中的值又丢向操作数栈顶
|
||||
- 这里使用`iinc`指令,将1号本地变量的值增加1(结束之后i的值就是11了)
|
||||
- 接着将操作数栈顶的值(操作数栈顶的值是10)存入2号本地变量(这下彻底知道i++到底干了啥才会先返回后自增了吧,从原理角度来说,实际上i是先自增了的,但由于这里取的是操作数栈中的值,所以说就得到了i之前的值)
|
||||
- 接着往下,我们看到++i是先直接将i的值自增1
|
||||
- 然后在将其值推向操作数栈顶
|
||||
|
||||

|
||||
|
||||
而从结果来看,`i++`操作确实是先返回再自增的,而字节码指令层面来说,却是截然相反的,只是结果一致罢了。
|
||||
|
||||
### ASM字节码编程
|
||||
|
||||
- 使用ASM框架(Java类)编写Class文件
|
||||
|
||||
- 既然字节码文件结构如此清晰,那么我们能否通过编程,来直接创建一个字节码文件呢?如果我们可以直接编写一个字节码文件,那么我们就可以省去编译的过程。ASM(某些JDK中内置)框架正是用于支持字节码编程的框架。
|
||||
|
||||
比如现在我们需要创建一个普通的Main类(暂时不写任何内容)
|
||||
|
||||
首先我们来看看如何通过编程创建一个Main类的字节码文件:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
首先需要获取`ClassWriter`对象,我们可以使用它来编辑类的字节码文件,在构造时需要传入参数:
|
||||
|
||||
- 0 这种方式不会自动计算操作数栈和局部临时变量表大小,需要自己手动来指定
|
||||
- ClassWriter.COMPUTE_MAXS(1) 这种方式会自动计算上述操作数栈和局部临时变量表大小,但需要手动触发。
|
||||
- ClassWriter.COMPUTE_FRAMES(2) 这种方式不仅会计算上述操作数栈和局部临时变量表大小,而且会自动计算StackMapFrames
|
||||
|
||||
这里我们使用`ClassWriter.COMPUTE_MAXS`即可。
|
||||
|
||||
接着我们首先需要指定类的一些基本信息:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
|
||||
//因为这里用到的常量比较多,所以说直接一次性静态导入:import static jdk.internal.org.objectweb.asm.Opcodes.*;
|
||||
writer.visit(V1_8, ACC_PUBLIC,"com/test/Main", null, "java/lang/Object",null);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里我们将字节码文件的版本设定位Java8,然后修饰符设定为`ACC_PUBLIC`代表`public class Main`,类名称注意要携带包名,标签设置为`null`,父类设定为Object类,然后没有实现任何接口,所以说最后一个参数也是`null`。
|
||||
|
||||
接着,一个简答的类字节码文件就创建好了,我们可以尝试将其进行保存
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
|
||||
writer.visit(V1_8, ACC_PUBLIC,"com/test/Main", null, "java/lang/Object",null);
|
||||
//调用visitEnd表示结束编辑
|
||||
writer.visitEnd();
|
||||
|
||||
try(FileOutputStream stream = new FileOutputStream("./Main.class")){
|
||||
stream.write(writer.toByteArray()); //直接通过ClassWriter将字节码文件转换为byte数组,并保存到根目录下
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,在IDEA中反编译的结果为:
|
||||
|
||||
```Java
|
||||
package com.test;
|
||||
|
||||
public class Main {
|
||||
}
|
||||
```
|
||||
|
||||
我们知道,正常的类在编译之后,如果没有手动添加构造方法,那么会自带一个无参构造,但是我们这个类中还没有,所以我们来手动添加一个无参构造方法:
|
||||
|
||||
```Java
|
||||
//通过visitMethod方法可以添加一个新的方法
|
||||
writer.visitMethod(ACC_PUBLIC, "<init>", "()V", null, null);
|
||||
```
|
||||
|
||||
可以看到反编译的结果中已经存在了我们的构造方法:
|
||||
|
||||
```Java
|
||||
package com.test;
|
||||
|
||||
public class Main {
|
||||
public Main() {
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
但是这样是不合法的,因为我们的构造方法还没有添加父类构造方法调用,所以说我们还需要在方法中添加父类构造方法调用指令:
|
||||
|
||||
```Plain
|
||||
public com.test.Main();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=1, args_size=1
|
||||
0: aload_0
|
||||
1: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
4: return
|
||||
LineNumberTable:
|
||||
line 11: 0
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 5 0 this Lcom/test/Main;
|
||||
```
|
||||
|
||||
我们需要对方法进行详细编辑:
|
||||
|
||||
```Java
|
||||
//通过MethodVisitor接收返回值,进行进一步操作
|
||||
MethodVisitor visitor = writer.visitMethod(ACC_PUBLIC, "<init>", "()V", null, null);
|
||||
//开始编辑代码
|
||||
visitor.visitCode();
|
||||
|
||||
//Label用于存储行号
|
||||
Label l1 = new Label();
|
||||
//当前代码写到哪行了,l1得到的就是多少行
|
||||
visitor.visitLabel(l1);
|
||||
//添加源码行数对应表(其实可以不用)
|
||||
visitor.visitLineNumber(11, l1);
|
||||
|
||||
//注意不同类型的指令需要用不同方法来调用,因为操作数不一致,具体的注释有写
|
||||
visitor.visitVarInsn(ALOAD, 0);
|
||||
visitor.visitMethodInsn(INVOKESPECIAL, "java/lang/Object", "<init>", "()V", false);
|
||||
visitor.visitInsn(RETURN);
|
||||
|
||||
Label l2 = new Label();
|
||||
visitor.visitLabel(l2);
|
||||
//添加本地变量表,这里加的是this关键字,但是方法中没用到,其实可以不加
|
||||
visitor.visitLocalVariable("this", "Lcom/test/Main;", null, l1, l2, 0);
|
||||
|
||||
//最后设定最大栈深度和本地变量数
|
||||
visitor.visitMaxs(1, 1);
|
||||
//结束编辑
|
||||
visitor.visitEnd();
|
||||
```
|
||||
|
||||
我们可以对编写好的class文件进行反编译,看看是不是和IDEA编译之后的结果差不多:
|
||||
|
||||
```Plain
|
||||
{
|
||||
public com.test.Main();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=1, args_size=1
|
||||
0: aload_0
|
||||
1: invokespecial #8 // Method java/lang/Object."<init>":()V
|
||||
4: return
|
||||
LocalVariableTable:
|
||||
Start Length Slot Name Signature
|
||||
0 5 0 this Lcom/test/Main
|
||||
LineNumberTable:
|
||||
line 11: 0
|
||||
}
|
||||
```
|
||||
|
||||
可以看到和之前的基本一致了,到此为止我们构造方法就编写完成了,接着我们来写一下main方法,一会我们就可以通过main方法来运行Java程序了。比如我们要编写这样一个程序:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) {
|
||||
int a = 10;
|
||||
System.out.println(a);
|
||||
}
|
||||
```
|
||||
|
||||
看起来很简单的一个程序对吧,但是我们如果手动去组装指令,会极其麻烦!首先main方法是一个静态方法,并且方法是public权限,然后还有一个参数`String[] args`,所以说我们这里要写的内容有点小多:
|
||||
|
||||
```Java
|
||||
//开始安排main方法
|
||||
MethodVisitor v2 = writer.visitMethod(ACC_PUBLIC | ACC_STATIC, "main", "([Ljava/lang/String;)V", null, null);
|
||||
v2.visitCode();
|
||||
//记录起始行信息
|
||||
Label l3 = new Label();
|
||||
v2.visitLabel(l3);
|
||||
v2.visitLineNumber(13, l3);
|
||||
|
||||
//首先是int a = 10的操作,执行指令依次为:
|
||||
// bipush 10 将10推向操作数栈顶
|
||||
// istore_1 将操作数栈顶元素保存到1号本地变量a中
|
||||
v2.visitIntInsn(BIPUSH, 10);
|
||||
v2.visitVarInsn(ISTORE, 1);
|
||||
Label l4 = new Label();
|
||||
v2.visitLabel(l4);
|
||||
//记录一下行信息
|
||||
v2.visitLineNumber(14, l4);
|
||||
|
||||
//这里是获取System类中的out静态变量(PrintStream接口),用于打印
|
||||
v2.visitFieldInsn(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
|
||||
//把a的值取出来
|
||||
v2.visitVarInsn(ILOAD, 1);
|
||||
//调用接口中的抽象方法println
|
||||
v2.visitMethodInsn(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(I)V", false);
|
||||
|
||||
//再次记录行信息
|
||||
Label l6 = new Label();
|
||||
v2.visitLabel(l6);
|
||||
v2.visitLineNumber(15, l6);
|
||||
|
||||
v2.visitInsn(RETURN);
|
||||
Label l7 = new Label();
|
||||
v2.visitLabel(l7);
|
||||
|
||||
//最后是本地变量表中的各个变量
|
||||
v2.visitLocalVariable("args", "[Ljava/lang/String;", null, l3, l7, 0);
|
||||
v2.visitLocalVariable("a", "I", null, l4, l7, 1);
|
||||
v2.visitMaxs(1, 2);
|
||||
//终于OK了
|
||||
v2.visitEnd();
|
||||
```
|
||||
|
||||
可以看到,虽然很简单的一个程序,但是如果我们手动去编写字节码,实际上是非常麻烦的,但是要实现动态代理之类的操作(可以很方便地修改字节码创建子类),是不是感觉又Get到了新操作(其实Spring实现动态代理的CGLib框架底层正是调用了ASM框架来实现的),所以说了解一下还是可以的,不过我们自己肯定是没多少玩这个的机会了。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 类加载机制
|
||||
|
||||
现在,我们已经了解了字节码文件的结构,以及JVM如何对内存进行管理,现在只剩下最后一个谜团等待解开了,也就是我们的类字节码文件到底是如何加载到内存中的,加载之后又会做什么事情。
|
||||
|
||||
### 类加载过程
|
||||
|
||||
- 详情
|
||||
|
||||
首先,要加载一个类,一定是出于某种目的的,比如我们要运行我们的Java程序,那么就必须要加载主类才能运行主类中的主方法,又或是我们需要加载数据库驱动,那么可以通过反射来将对应的数据库驱动类进行加载。
|
||||
|
||||
所以,一般在这些情况下,如果类没有被加载,那么会被自动加载:
|
||||
|
||||
- 使用new关键字创建对象时
|
||||
- 使用某个类的静态成员(包括方法和字段)的时候(当然,final类型的静态字段有可能在编译的时候被放到了当前类的常量池中,这种情况下是不会触发自动加载的)
|
||||
- 使用反射对类信息进行获取的时候(之前的数据库驱动就是这样的)
|
||||
- 加载一个类的子类时
|
||||
- 加载接口的实现类,且接口带有`default`的方法默认实现时
|
||||
|
||||
比如这种情况,那么需要用到另一个类中的成员字段,所以就必须将另一个类加载之后才能访问:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
System.out.println(Test.str);
|
||||
}
|
||||
|
||||
public static class Test{
|
||||
static {
|
||||
System.out.println("我被初始化了!");
|
||||
}
|
||||
|
||||
public static String str = "都看到这里了,不给个三连+关注吗?";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里我们就演示一个不太好理解的情况,我们现在将静态成员变量修改为final类型的:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
System.out.println(Test.str);
|
||||
}
|
||||
|
||||
public static class Test{
|
||||
static {
|
||||
System.out.println("我被初始化了!");
|
||||
}
|
||||
|
||||
public final static String str = "都看到这里了,不给个三连+关注吗?";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,在主方法中,我们使用了Test类的静态成员变量,并且此静态成员变量是一个final类型的,也就是说不可能再发生改变。那么各位觉得,Test类会像上面一样被初始化吗?
|
||||
|
||||
按照正常逻辑来说,既然要用到其他类中的字段,那么肯定需要加载其他类,但是这里我们结果发现,并没有对Test类进行加载,那么这是为什么呢?我们来看看Main类编译之后的字节码指令就知道了:
|
||||
|
||||

|
||||
|
||||
很明显,这里使用的是`ldc`指令从常量池中将字符串取出并推向操作数栈顶,也就是说,在编译阶段,整个`Test.str`直接被替换为了对应的字符串(因为final不可能发生改变的,编译就会进行优化,直接来个字符串比你去加载类在获取快得多不是吗,反正结果都一样),所以说编译之后,实际上跟Test类半毛钱关系都没有了。
|
||||
|
||||
所以说,当你在某些情况下疑惑为什么类加载了或是没有加载时,可以从字节码指令的角度去进行分析,一般情况下,只要遇到`new`、`getstatic`、`putstatic`、`invokestatic`这些指令时,都会进行类加载,比如:
|
||||
|
||||

|
||||
|
||||
这里很明显,是一定会将Test类进行加载的。除此之外,各位也可以试试看数组的定义会不会导致类被加载。
|
||||
|
||||
好了,聊完了类的加载触发条件,我们接着来看一下类的详细加载流程。
|
||||
|
||||

|
||||
|
||||
首先类的生命周期一共有7个阶段,而首当其冲的就是加载,加载阶段需要获取此类的二进制数据流,比如我们要从硬盘中读取一个class文件,那么就可以通过文件输入流来获取类文件的`byte[]`,也可以是其他各种途径获取类文件的输入流,甚至网络传输并加载一个类也不是不可以。然后交给类加载器进行加载(类加载器可以是JDK内置的,也可以是开发者自己撸的,后面会详细介绍)类的所有信息会被加载到方法区中,并且在堆内存中会生成一个代表当前类的Class类对象(那么思考一下,同一个Class文件加载的类,是唯一存在的吗?),我们可以通过此对象以及反射机制来访问这个类的各种信息。
|
||||
|
||||
数组类要稍微特殊一点,通过前面的检验,我没发现数组在创建后是不会导致类加载的,数组类型本身不会通过类加载器进行加载的,不过你既然要往里面丢对象进去,那最终依然是要加载类的。
|
||||
|
||||
接着我们来看验证阶段,验证阶段相当于是对加载的类进行一次规范校验(因为一个类并不一定是由我们使用IDEA编译出来的,有可能是像我们之前那样直接用ASM框架写的一个),如果说类的任何地方不符合虚拟机规范,那么这个类是不会验证通过的,如果没有验证机制,那么一旦出现危害虚拟机的操作,整个程序会出现无法预料的后果。
|
||||
|
||||
验证阶段,首先是文件格式的验证:
|
||||
|
||||
- 是否魔数为CAFEBABE开头。
|
||||
- 主、次版本号是否可以由当前Java虚拟机运行
|
||||
- Class文件各个部分的完整性如何。
|
||||
- ...
|
||||
|
||||
有关类验证的详细过程,可以参考《深入理解Java虚拟机 第三版》268页。
|
||||
|
||||
接下来就是准备阶段了,这个阶段会为类变量分配内存,并为一些字段设定初始值,注意是系统规定的初始值,不是我们手动指定的初始值。
|
||||
|
||||
再往下就是解析阶段,此阶段是将常量池内的符号引用替换为直接引用的过程,也就是说,到这个时候,所有引用变量的指向都是已经切切实实地指向了内存中的对象了。
|
||||
|
||||
到这里,链接过程就结束了,也就是说这个时候类基本上已经完成大部分内容的初始化了。
|
||||
|
||||
最后就是真正的初始化阶段了,从这里开始,类中的Java代码部分,才会开始执行,还记得我们之前介绍的`<clinit>`方法吗,它就是在这个时候执行的,比如我们的类中存在一个静态成员变量,并且赋值为10,或是存在一个静态代码块,那么就会自动生成一个`<clinit>`方法来进行赋值操作,但是这个方法是自动生成的。
|
||||
|
||||
全部完成之后,我们的类就算是加载完成了。
|
||||
|
||||
|
||||
### 类加载器
|
||||
|
||||
- 详情
|
||||
|
||||
Java提供了类加载器,以便我们自己可以更好地控制类加载,我们可以自定义类加载器,也可以使用官方自带的类加载器去加载类。对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性。
|
||||
|
||||
也就是说,一个类可以由不同的类加载器加载,并且,不同的类加载器加载的出来的类,即使来自同一个Class文件,也是不同的,只有两个类来自同一个Class文件并且是由同一个类加载器加载的,才能判断为是同一个。默认情况下,所有的类都是由JDK自带的类加载器进行加载。
|
||||
|
||||
比如,我们先创建一个Test类用于测试:
|
||||
|
||||
```Java
|
||||
package com.test;
|
||||
|
||||
public class Test {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
接着我们自己实现一个ClassLoader来加载我们的Test类,同时使用官方默认的类加载器来加载:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) throws ReflectiveOperationException {
|
||||
Class<?> testClass1 = Main.class.getClassLoader().loadClass("com.test.Test");
|
||||
CustomClassLoader customClassLoader = new CustomClassLoader();
|
||||
Class<?> testClass2 = customClassLoader.loadClass("com.test.Test");
|
||||
|
||||
//看看两个类的类加载器是不是同一个
|
||||
System.out.println(testClass1.getClassLoader());
|
||||
System.out.println(testClass2.getClassLoader());
|
||||
|
||||
//看看两个类是不是长得一模一样
|
||||
System.out.println(testClass1);
|
||||
System.out.println(testClass2);
|
||||
|
||||
//两个类是同一个吗?
|
||||
System.out.println(testClass1 == testClass2);
|
||||
|
||||
//能成功实现类型转换吗?
|
||||
Test test = (Test) testClass2.newInstance();
|
||||
}
|
||||
|
||||
static class CustomClassLoader extends ClassLoader {
|
||||
@Override
|
||||
public Class<?> loadClass(String name) throws ClassNotFoundException {
|
||||
try (FileInputStream stream = new FileInputStream("./target/classes/"+name.replace(".", "/")+".class")){
|
||||
byte[] data = new byte[stream.available()];
|
||||
stream.read(data);
|
||||
if(data.length == 0) return super.loadClass(name);
|
||||
return defineClass(name, data, 0, data.length);
|
||||
} catch (IOException e) {
|
||||
return super.loadClass(name);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过结果我们发现,即使两个类是同一个Class文件加载的,只要类加载器不同,那么这两个类就是不同的两个类。
|
||||
|
||||
所以说,我们当时在JavaSE阶段讲解的每个类都在堆中有一个唯一的Class对象放在这里来看,并不完全正确,只是当前为了防止各位初学者搞混。
|
||||
|
||||
实际上,JDK内部提供的类加载器一共有三个,比如上面我们的Main类,其实是被AppClassLoader加载的,而JDK内部的类,都是由BootstrapClassLoader加载的,这其实就是为了实现双亲委派机制而做的。
|
||||
|
||||

|
||||
|
||||
有关双亲委派机制,我们在JavaSE阶段反射板块已经讲解过了,所以说这就不多做介绍了。
|
||||
|
||||
- 为什么要自定义类加载器
|
||||
|
||||
Java 提供自定义类加载器的机制有几个重要的原因。让我们深入探讨这个问题:
|
||||
|
||||
1. 扩展类加载方式:
|
||||
- 默认的类加载器从文件系统加载类,但有时我们需要从其他源加载类,如网络、数据库等。
|
||||
- 自定义类加载器允许我们定义特殊的类加载逻辑。
|
||||
2. 实现类的隔离:
|
||||
- 在同一个 JVM 中,不同的应用可能需要使用同一个类的不同版本。
|
||||
- 自定义类加载器可以为每个应用加载独立的类版本,实现类的隔离。
|
||||
3. 提高安全性:
|
||||
- 可以在加载类之前进行安全检查,如验证数字签名。
|
||||
- 可以实现自定义的安全策略,控制哪些类可以被加载。
|
||||
4. 实现热部署:
|
||||
- 在不重启 JVM 的情况下,通过自定义类加载器可以重新加载更新后的类。
|
||||
- 这在需要频繁更新的系统中非常有用,如开发环境或某些服务器应用。
|
||||
5. 懒加载:
|
||||
- 可以实现按需加载类,而不是在启动时就加载所有类。
|
||||
- 这可以提高应用的启动速度和资源利用效率。
|
||||
6. 修改字节码:
|
||||
- 在加载类的过程中,可以动态修改类的字节码。
|
||||
- 这对于一些特殊需求如性能监控、代码增强等非常有用。
|
||||
7. 实现插件化架构:
|
||||
- 在插件系统中,可以使用自定义类加载器来加载和管理插件。
|
||||
- 这样可以实现插件的动态加载和卸载。
|
||||
8. 处理特殊的类加载需求:
|
||||
- 某些框架或库可能需要特殊的类加载机制。
|
||||
- 例如,一些 Web 服务器使用自定义类加载器来隔离不同的 Web 应用。
|
||||
9. 跨应用程序边界共享类:
|
||||
- 在某些情况下,可能需要在不同的应用程序间共享类,自定义类加载器可以实现这一点。
|
||||
10. 实现类的版本控制:
|
||||
- 可以加载特定版本的类,而不受系统类路径中可能存在的其他版本影响。
|
||||
11. 优化类加载性能:
|
||||
- 在某些情况下,自定义的类加载策略可能比默认的更高效。
|
||||
12. 动态代理和AOP的实现:
|
||||
- 一些高级的编程技术,如动态代理和面向切面编程(AOP),often利用自定义类加载器来动态生成和加载类。
|
||||
|
||||
示例:自定义网络类加载器
|
||||
|
||||
以下是一个简单的自定义类加载器示例,它从网络加载类:
|
||||
|
||||
```Java
|
||||
public class NetworkClassLoader extends ClassLoader {
|
||||
private String baseUrl;
|
||||
|
||||
public NetworkClassLoader(String baseUrl) {
|
||||
this.baseUrl = baseUrl;
|
||||
}
|
||||
|
||||
@Override
|
||||
protected Class<?> findClass(String name) throws ClassNotFoundException {
|
||||
try {
|
||||
String url = baseUrl + "/" + name.replace('.', '/') + ".class";
|
||||
URL classUrl = new URL(url);
|
||||
try (InputStream is = classUrl.openStream()) {
|
||||
ByteArrayOutputStream baos = new ByteArrayOutputStream();
|
||||
int ch;
|
||||
while ((ch = is.read()) != -1) {
|
||||
baos.write(ch);
|
||||
}
|
||||
byte[] bytes = baos.toByteArray();
|
||||
return defineClass(name, bytes, 0, bytes.length);
|
||||
}
|
||||
} catch (IOException e) {
|
||||
throw new ClassNotFoundException("Class " + name + " not found", e);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这个例子展示了如何创建一个从网络加载类的自定义类加载器。它从指定的 URL 下载类文件,然后使用 `defineClass` 方法将字节码转换为 Class 对象。
|
||||
|
||||
总结来说,Java 提供自定义类加载器机制,极大地增强了 Java 平台的灵活性和可扩展性,使得开发者能够实现各种复杂的类加载策略,满足不同场景下的特殊需求。
|
||||
{kind=link}
|
After Width: | Height: | Size: 213 KiB |
{kind=link}
|
After Width: | Height: | Size: 232 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
{kind=link}
|
After Width: | Height: | Size: 303 KiB |
{kind=link}
|
After Width: | Height: | Size: 628 KiB |
{kind=link}
|
After Width: | Height: | Size: 81 KiB |
{kind=link}
|
After Width: | Height: | Size: 583 KiB |
{kind=link}
|
After Width: | Height: | Size: 236 KiB |
{kind=link}
|
After Width: | Height: | Size: 258 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
{kind=link}
|
After Width: | Height: | Size: 164 KiB |
{kind=link}
|
After Width: | Height: | Size: 110 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.2 MiB |
{kind=link}
|
After Width: | Height: | Size: 557 KiB |
{kind=link}
|
After Width: | Height: | Size: 397 KiB |
{kind=link}
|
After Width: | Height: | Size: 139 KiB |
{kind=link}
|
After Width: | Height: | Size: 123 KiB |
{kind=link}
|
After Width: | Height: | Size: 87 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
{kind=link}
|
After Width: | Height: | Size: 390 KiB |
{kind=link}
|
After Width: | Height: | Size: 459 KiB |
{kind=link}
|
After Width: | Height: | Size: 152 KiB |
{kind=link}
|
After Width: | Height: | Size: 532 KiB |
{kind=link}
|
After Width: | Height: | Size: 392 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.3 MiB |
{kind=link}
|
After Width: | Height: | Size: 84 KiB |
{kind=link}
|
After Width: | Height: | Size: 340 KiB |
{kind=link}
|
After Width: | Height: | Size: 622 KiB |
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
{kind=link}
|
After Width: | Height: | Size: 153 KiB |
{kind=link}
|
After Width: | Height: | Size: 108 KiB |
{kind=link}
|
After Width: | Height: | Size: 273 KiB |
{kind=link}
|
After Width: | Height: | Size: 253 KiB |
@@ -0,0 +1,102 @@
|
||||
---
|
||||
title: JVM笔记
|
||||
date: 2024-08-25
|
||||
tags: [JVM]
|
||||
---
|
||||
|
||||
|
||||
[前篇](前篇.md)
|
||||
|
||||
[中篇](中篇.md)
|
||||
|
||||
[后篇](后篇.md)
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
软引用(Soft Reference)和弱引用(Weak Reference)都是 Java 中提供的引用类型,它们的主要作用是控制垃圾回收机制如何处理引用对象。它们都属于 **java.lang.ref** 包中,并且在不同的场景中可以避免内存泄漏,并帮助实现更灵活的内存管理。
|
||||
|
||||
### 1. **软引用(Soft Reference)**
|
||||
|
||||
- **定义**:软引用是一种在内存充足时不会被垃圾回收器回收的引用类型,只有在内存不足时,垃圾回收器才会回收这些对象。
|
||||
- **特点**:
|
||||
- 软引用通常用于实现内存敏感的缓存。
|
||||
- 如果 JVM 运行时内存不足,软引用指向的对象会被回收。
|
||||
- 软引用的对象会在垃圾回收时被清理,但如果 JVM 内存充足,它们会一直存在。
|
||||
- **用途**:
|
||||
- 用于内存缓存,例如当内存不足时,缓存中的一些对象可以被回收,但并不在内存充足时轻易回收。
|
||||
- **如何使用**:
|
||||
- 软引用的对象通过 `SoftReference` 类来创建。
|
||||
- 一般结合 `SoftReference` 和 `SoftReference.get()` 来使用。
|
||||
|
||||
```Java
|
||||
import java.lang.ref.*;
|
||||
|
||||
public class SoftReferenceExample {
|
||||
public static void main(String[] args) {
|
||||
String str = new String("Hello");
|
||||
SoftReference<String> softRef = new SoftReference<>(str);
|
||||
|
||||
// 在内存充足时,softRef.get() 可以访问对象
|
||||
System.out.println(softRef.get()); // 输出:Hello
|
||||
|
||||
str = null; // 将原始引用设为 null
|
||||
|
||||
// 如果 JVM 内存不足,softRef.get() 可能返回 null
|
||||
System.gc(); // 触发垃圾回收
|
||||
|
||||
System.out.println(softRef.get()); // 输出:null (如果对象被回收)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2. **弱引用(Weak Reference)**
|
||||
|
||||
- **定义**:弱引用是一种比软引用更弱的引用类型。弱引用指向的对象,在垃圾回收时只要没有强引用指向它,就会被回收。
|
||||
- **特点**:
|
||||
- 弱引用的对象会在下一次垃圾回收时被回收,无论内存是否充足。
|
||||
- 弱引用常用于实现那些不阻止对象回收的场景,如在某些缓存机制中,用来缓存不需要强引用的对象。
|
||||
- **用途**:
|
||||
- 用于对象的缓存或者在一些不需要长期存在的资源管理中。
|
||||
- 典型的应用是 `**ThreadLocal**` 类,它使用弱引用来存储每个线程的局部变量。
|
||||
- **如何使用**:
|
||||
- 使用 `WeakReference` 类创建弱引用对象。
|
||||
- 和软引用一样,通过 `WeakReference.get()` 方法来获取对象。
|
||||
|
||||
```Java
|
||||
import java.lang.ref.*;
|
||||
|
||||
public class WeakReferenceExample {
|
||||
public static void main(String[] args) {
|
||||
String str = new String("Hello");
|
||||
WeakReference<String> weakRef = new WeakReference<>(str);
|
||||
|
||||
// 在没有强引用时,weakRef.get() 会返回 null
|
||||
System.out.println(weakRef.get()); // 输出:Hello
|
||||
|
||||
str = null; // 将原始引用设为 null
|
||||
|
||||
System.gc(); // 强制触发垃圾回收
|
||||
|
||||
System.out.println(weakRef.get()); // 输出:null (对象被回收)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3. **软引用与弱引用的区别**
|
||||
|
||||
| | | |
|
||||
|---|---|---|
|
||||
|特性|软引用(Soft Reference)|弱引用(Weak Reference)|
|
||||
|回收时机|仅在内存不足时被回收|一旦没有强引用指向,立刻被垃圾回收|
|
||||
|内存敏感性|相对更灵活,在内存充足时保持对象存在|对象更容易被回收,几乎没有内存保护|
|
||||
|使用场景|实现内存敏感缓存,如图片缓存、对象缓存|适用于短期存活的数据,例如 `ThreadLocal`|
|
||||
|对象存活周期|在内存充足时,可能会长时间存在|对象几乎总是在短时间内被回收|
|
||||
|
||||
### 4. **总结**
|
||||
|
||||
- **软引用**:在内存不足时会被回收,适用于内存敏感的缓存场景。
|
||||
- **弱引用**:一旦没有强引用指向的对象就会被垃圾回收器回收,适用于短期有效的对象,如线程局部存储(`ThreadLocal`)等。
|
||||
|
||||
两者都可以帮助实现内存管理,但选择哪个取决于你的实际需求。如果你希望缓存数据可以在内存充足时长时间保持,但在内存紧张时及时回收,可以使用软引用;如果对象不需要长期保存且希望快速回收,应该选择弱引用。
|
||||
{kind=link}
|
After Width: | Height: | Size: 406 KiB |
@@ -0,0 +1,472 @@
|
||||
---
|
||||
title: 垃圾回收机制
|
||||
date: 2024-08-25
|
||||
tags: [JVM]
|
||||
---
|
||||
|
||||
|
||||
## 对象存活判定算法
|
||||
|
||||
首先我们来套讨论第一个问题,也就是:对象在什么情况下可以被判定为不再使用已经可以回收了?这里就需要提到以下几种垃圾回收算法了。
|
||||
|
||||

|
||||
|
||||
### 引用计数法
|
||||
|
||||
我们知道,如果我们要经常操作一个对象,那么首先一定会创建一个引用变量:
|
||||
|
||||
```Java
|
||||
//str就是一个引用类型的变量,它持有对后面字符串对象的引用,可以代表后面这个字符串对象本身
|
||||
String str = "lbwnb";
|
||||
|
||||
//str.xxxxx...
|
||||
```
|
||||
|
||||
实际上,我们会发现,只要一个对象还有使用价值,我们就会通过它的引用变量来进行操作,那么可否这样判断一个对象是否还需要被使用:
|
||||
|
||||
- 每个对象都包含一个 **引用计数器**,用于存放引用计数(其实就是存放被引用的次数)
|
||||
- 每当有一个地方**引用此对象时**,引用计数`+1`
|
||||
- 当引用失效( 比如离开了局部变量的作用域或是引用被设定为`null`)时,引用计数`1`
|
||||
- 当引用计数为`0`时,表示此对象不可能再被使用,因为这时我们已经没有任何方法可以得到此对象的引用了
|
||||
|
||||
**缺陷**:但是这样存在一个问题,如果两个对象相互引用呢?
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Test a = new Test();
|
||||
Test b = new Test();
|
||||
|
||||
a.another = b;
|
||||
b.another = a;
|
||||
|
||||
//这里直接把a和b赋值为null,这样前面的两个对象我们不可能再得到了
|
||||
a = b = null;
|
||||
}
|
||||
|
||||
private static class Test{
|
||||
Test another;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
按照引用计数算法,那么当出现以上情况时,虽然我们无法在得到此对象的引用了,并且此对象我们也无需再使用,但是由于这两个对象直接存在相互引用的情况,那么引用计数器的值将会永远是`1`,但是实际上此对象已经没有任何用途了。所以引用计数法并不是最好的解决方案。
|
||||
|
||||
### 可达性分析算法⭐
|
||||
|
||||
目前比较主流的编程语言(包括Java),一般都会使用可达性分析算法来判断对象是否存活,它采用了类**似于树结构的搜索机制**。
|
||||
|
||||
- 首先每个对象的引用都有机会成为树的根节点(GC Roots),可以被选定作为根节点条件如下:
|
||||
- 位于虚拟机栈的栈帧中的本地变量表中所引用到的对象(其实就是我们方法中的局部变量)同样也包括本地方法栈中JNI引用的对象。
|
||||
- 类的静态成员变量引用的对象。
|
||||
- 方法区中,常量池里面引用的对象,比如我们之前提到的`String`类型对象。
|
||||
- 被添加了锁的对象(比如synchronized关键字)
|
||||
- 虚拟机内部需要用到的对象。
|
||||
|
||||

|
||||
|
||||
- 一旦已经存在的根节点不满足存在的条件时,那么根节点与对象之间的连接将被断开。此时虽然对象1仍存在对其他对象的引用,但是由于其没有任何根节点引用,所以此对象即可被判定为不再使用。比如某个方法中的局部变量引用,在方法执行完成返回之后:
|
||||
|
||||

|
||||
|
||||
- 这样就能很好地解决我们刚刚提到的循环引用问题,我们再来重现一下出现循环引用的情况:
|
||||
|
||||

|
||||
|
||||
可以看到,对象1和对象2依然是存在循环引用的,但是只有他们各自的GC Roots断开,那么就会变成下面这样:
|
||||
|
||||

|
||||
|
||||
所以,我们最后进行一下总结:如果某个对象==无法到达任何GC Roots==,则证明此对象是不可能再被使用的。
|
||||
|
||||
|
||||
|
||||
- 首先会从 GC Roots 出发,标记所有存活的对象
|
||||
|
||||
### 最终判定
|
||||
|
||||
- 虽然在经历了可达性分析算法之后基本可能判定哪些对象能够被回收,但是并不代表此对象一定会被回收,我们依然可以==在最终判定阶段对其进行挽留==。
|
||||
- `Object`类中的`**finalize()**`方法正是最终判定方法
|
||||
|
||||
- 重写`finalize`方法详解
|
||||
|
||||
```Java
|
||||
/**
|
||||
* Called by the garbage collector on an object when garbage collection
|
||||
* determines that there are no more references to the object.
|
||||
* A subclass overrides the {@code finalize} method to dispose of
|
||||
* system resources or to perform other cleanup.
|
||||
* ...
|
||||
*/
|
||||
protected void finalize() throws Throwable { }
|
||||
```
|
||||
|
||||
此方法正是最终判定方法,如果子类重写了此方法,那么子类对象在被判定为可回收时,会进行二次确认,也就是执行`finalize()`方法,而在此方法中,当前对象是完全有可能重新建立GC Roots的!所以,如果在二次确认后对象不满足可回收的条件,那么此对象不会被回收,巧妙地逃过了垃圾回收的命运。比如下面这个例子:
|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
private static Test a;
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
a = new Test();
|
||||
|
||||
//这里直接把a赋值为null,这样前面的对象我们不可能再得到了
|
||||
a = null;
|
||||
|
||||
//手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行)
|
||||
System.gc();
|
||||
|
||||
//等垃圾回收一下()
|
||||
Thread.sleep(1000);
|
||||
|
||||
//我们来看看a有没有被回收
|
||||
System.out.println(a);
|
||||
}
|
||||
|
||||
private static class Test{
|
||||
@Override
|
||||
protected void finalize() throws Throwable {
|
||||
System.out.println(this+" 开始了它的救赎之路!");
|
||||
a = this;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
注意`finalize()`方法并不是在主线程调用的,而是虚拟机自动建立的一个低优先级的`Finalizer`线程(正是因为优先级比较低,所以前面才需要等待1秒钟)进行处理,我们可以稍微修改一下看看:
|
||||
|
||||
```Java
|
||||
private static class Test{
|
||||
@Override
|
||||
protected void finalize() throws Throwable {
|
||||
System.out.println(Thread.currentThread());
|
||||
a = this;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```Plain
|
||||
Thread[Finalizer,8,system]
|
||||
com.test.Main$Test@232204a1
|
||||
```
|
||||
|
||||
同时,同一个对象的`finalize()`方法只会有一次调用机会,也就是说,如果我们连续两次这样操作,那么第二次,对象必定被回收:
|
||||
|
||||
```Java
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
a = new Test();
|
||||
//这里直接把a赋值为null,这样前面的对象我们不可能再得到了
|
||||
a = null;
|
||||
//手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行)
|
||||
System.gc();
|
||||
//等垃圾回收一下
|
||||
Thread.sleep(1000);
|
||||
|
||||
System.out.println(a);
|
||||
//这里直接把a赋值为null,这样前面的对象我们不可能再得到了
|
||||
a = null;
|
||||
//手动申请执行垃圾回收操作(注意只是申请,并不一定会执行,但是一般情况下都会执行)
|
||||
System.gc();
|
||||
//等垃圾回收一下
|
||||
Thread.sleep(1000);
|
||||
|
||||
System.out.println(a);
|
||||
}
|
||||
```
|
||||
|
||||
当然,`finalize()`方法也并不是专门防止对象被回收的,我们可以使用它来释放一些程序使用中的资源等。
|
||||
|
||||
最后,总结成一张图:二次调用`finalize()`直接回收
|
||||
|
||||

|
||||
|
||||
- 当然,除了堆中的对象以外,方法区中的数据也是可以被垃圾回收的,但是回收条件比较严格
|
||||
|
||||
## 哪些对象需要进行回收
|
||||
|
||||
**概述**:前面我们介绍了对象存活判定算法,现在我们已经可以准确地知道堆中的哪些对象可以被回收了,那么,接下来就该考虑如何对对象进行回收了,垃圾收集器会不定期地检查堆中的对象,查看它们是否满足被回收的条件。我们该如何对这些对象进行回收,是一个一个判断是否需要回收吗?
|
||||
|
||||
### 分代收集机制
|
||||
|
||||
- 属于一种**内存管理机制**,使内存的利用率大大提高
|
||||
|
||||
- 产生原因
|
||||
- 实际上,如果我们对堆中的每一个对象都依次判断是否需要回收,这样的效率其实是很低的,那么有没有更好地回收机制呢?第一步,我们可以对堆中的对象进行分代管理。
|
||||
- 比如某些对象,在多次垃圾回收时,都未被判定为可回收对象,我们完全可以将这一部分对象放在一起,并让垃圾收集器减少回收此区域对象的频率,这样就能很好地提高垃圾回收的效率了。
|
||||
|
||||
- 因此,Java虚拟机将堆内存划分为**新生代**、**老年代**和**永久代**(其中永久代是HotSpot虚拟机特有的概念,在JDK8之前方法区实际上就是采用的永久代作为实现,而在JDK8之后,方法区由元空间实现,并且使用的是本地内存,容量大小取决于物理机实际大小)这里我们主要讨论的是**新生代**和**老年代**。
|
||||
- 结构:不同的分代内存回收机制也存在一些不同之处,在HotSpot虚拟机中,新生代被划分为三块,一块较大的**Eden空间**和两块较小的**Survivor空间**,默认比例为8:1:1,==老年代的GC频率相对较低==,永久代一般存放类信息等(其实就是方法区的实现)如图所示:
|
||||
|
||||

|
||||
|
||||
- ⭐那么它是如何运作的呢?
|
||||
- 当对象创建时,它会进入==Eden==区,如果是大对象会被直接丢进老年代,当==Eden区空间不足时==,触发**Minor GC**(次要垃圾回收,主要进行新生代区域的垃圾收集),每经历一轮GC,对象年龄就加1(对象的年龄通常存储在对象头中,一般是4位,最大值为`15`),==超过15岁,进入老年代,====GC详情如下==
|
||||
- 通过**复制算法**来完成**Minor GC**,==From和To分区是服务该算法的==
|
||||
- 过程:对象区域转移
|
||||
- **标记存活对象**:通过可达性算法分析
|
||||
- 在==Eden区和From Survivor区==中,JVM首先标记哪些对象仍然存活
|
||||
- **复制存活对象**:
|
||||
- JVM将存活对象从Eden区和From Survivor区复制到==To Survivor==区,年龄加1。如果To Survivor区中无法容纳所有存活对象,部分存活对象可能会被直接晋升到老年代
|
||||
- **清空Eden区和From Survivor区**:
|
||||
- 复制完存活对象后,Eden区和From Survivor区中的所有内容都会被清空(即所有未被标记为存活的对象会被视为垃圾并被丢弃)。
|
||||
- **交换From和To区域**:
|
||||
- 在GC完成后,To Survivor区会变成新的From Survivor区,而原来的From Survivor区被清空,成为新的To Survivor区。
|
||||
- 为什么使用复制算法
|
||||
- 复制算法在移动对象的同时,自然地实现了**内存整理**。
|
||||
- 存活对象被复制到新的区域时,它们会紧密排列,**消除了碎片**。
|
||||
- 因为新生代中大多数对象生命周期短,存活率低,**复制少量存活对象**比清理大量死亡对象更高效
|
||||
|
||||
- 垃圾收集也分为:
|
||||
- Minor GC - 次要垃圾回收,主要进行新生代区域的垃圾收集。
|
||||
- 触发条件:新生代的Eden区容量已满时。
|
||||
- Major GC - 主要垃圾回收,主要进行老年代的垃圾收集。
|
||||
- Full GC - 完全垃圾回收,对整个Java堆内存和方法区进行垃圾回收。
|
||||
- 触发条件1:每次晋升到老年代的对象平均大小大于老年代剩余空间
|
||||
- 触发条件2:Minor GC后存活的对象超过了老年代剩余空间
|
||||
- 触发条件3:永久代内存不足(JDK8之前)
|
||||
- 触发条件4:手动调用`System.gc()`方法
|
||||
|
||||
- 测试
|
||||
|
||||
我们可以添加启动参数来查看JVM的GC日志:
|
||||
|
||||

|
||||
|
||||
```Java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Object o = new Object();
|
||||
o = null;
|
||||
System.gc();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```Plain
|
||||
[GC (System.gc()) [PSYoungGen: 2621K->528K(76288K)] 2621K->528K(251392K), 0.0006874 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
|
||||
[Full GC (System.gc()) [PSYoungGen: 528K->0K(76288K)] [ParOldGen: 0K->332K(175104K)] 528K->332K(251392K), [Metaspace: 3073K->3073K(1056768K)], 0.0022693 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
|
||||
Heap
|
||||
PSYoungGen total 76288K, used 3277K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000)
|
||||
eden space 65536K, 5% used [0x000000076ab00000,0x000000076ae334d8,0x000000076eb00000)
|
||||
from space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000)
|
||||
to space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000)
|
||||
ParOldGen total 175104K, used 332K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000)
|
||||
object space 175104K, 0% used [0x00000006c0000000,0x00000006c00532d8,0x00000006cab00000)
|
||||
Metaspace used 3096K, capacity 4496K, committed 4864K, reserved 1056768K
|
||||
class space used 333K, capacity 388K, committed 512K, reserved 1048576K
|
||||
```
|
||||
|
||||
|
||||
### 空间分配担保
|
||||
|
||||
- 是一种空间不足的弥补措施
|
||||
|
||||
- 产生原因
|
||||
|
||||
我们可以思考一下,有没有这样一种极端情况(正常情况下新生代的回收率是很高的,所以说不用太担心会经常出现这种问题),在一次GC后,新生代Eden区仍然存在大量的对象(因为GC之后存活对象会进入到一个Survivor区,但是==很明显这时已经超出Survivor区的容量==了,肯定是装不下的)那么现在该怎么办?这时就需要用到**空间分配担保机制**了,可以把==Survivor区无法容纳的对象直接送到老年代==,让老年代进行分配担保(当然老年代也得装得下才行)在现实生活中,贷款会指定担保人,就是当借款人还不起钱的时候由担保人来还钱。好,那既然新生代装不下就丢给老年代,那么要是==老年代也装不下新生代的数据==呢?这时,老年代肯定担保人是当不成了,那么这样的话,首先会判断一下之前的每次垃圾回收==进入老年代的平均大小是否小于当前老年代的剩余空间==,如果小于,那么说明也许可以放得下(不过也仅仅是也许,依然有可能放不下,因为判断的实际上只是平均值,万一这一次突然非常大呢),否则,会先来一次Full GC,进行一次大规模垃圾回收,来尝试腾出空间,再次判断老年代是否有空间存放,要是还是装不下,直接抛出OOM错误,摆烂。
|
||||
|
||||
|
||||
最后,我们来总结一下一次Minor GC的整个过程:
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## 收集过程
|
||||
|
||||
### 标记-清除算法
|
||||
|
||||
前面我们已经了解了整个堆内存实际上是以分代收集机制为主,但是依然没有讲到具体的收集过程,那么,具体的回收过程又是什么样的呢?首先我们来了解一下最古老的`标记-清除`算法。
|
||||
|
||||
首先==标记出所有需要回收的对象==,然后再==依次回收掉被标记的对象==,或是标记出所有不需要回收的对象,只回收未标记的对象。实际上这种算法是非常基础的,并且最易于理解的(这里对象我就以一个方框代替了,当然实际上存放是我们前说到的GC Roots形式)
|
||||
|
||||

|
||||
|
||||
虽然此方法非常简单,但是缺点也是非常明显的 ,首先如果内存中存在大量的对象,那么可能就会存在大量的标记,并且大规模进行清除。并且一次标记清除之后,连续的内存空间可能会出现许许多多的空隙,**碎片化会导致连续内存空间利用率降低**。
|
||||
|
||||
### 标记-复制算法
|
||||
|
||||
既然标记清除算法在面对大量对象时效率低,那么我们可以采用标记-复制算法。它将容量分为同样大小的两块区域,
|
||||
|
||||
标记复制算法,实际上就是将内存区域划分为大小相同的两块区域,每次只使用其中的一块区域,每次垃圾回收结束后,将所有存活的对象全部复制到另一块区域中,并一次性清空当前区域。虽然浪费了一些时间进行复制操作,但是这样能够很好地解决对象大面积回收后空间碎片化严重的问题。
|
||||
|
||||

|
||||
|
||||
这种算法就非常适用于新生代(因为新生代的回收效率极高,一般不会留下太多的对象)的垃圾回收,而我们之前所说的**新生代Survivor区其实就是这个思路**,包括8:1:1的比例也正是为了对标记复制算法进行优化而采取的。
|
||||
|
||||
### 标记-整理(压缩)算法
|
||||
|
||||
虽然标记-复制算法能够很好地应对新生代高回收率的场景,但是放到老年代,它就显得很鸡肋了。我们知道,一般长期都回收不到的对象,才有机会进入到老年代,所以老年代一般都是些钉子户,可能一次GC后,仍然存留很多对象。而标记复制算法会在GC后完整复制整个区域内容,并且会折损50%的区域,显然这并不适用于老年代。
|
||||
|
||||
那么我们能否这样,在标记所有待回收对象之后,不急着去进行回收操作,而是将所有待回收的对象整齐排列在一段内存空间中,而需要回收的对象全部往后丢,这样,前半部分的所有对象都是无需进行回收的,而后半部分直接一次性清除即可。
|
||||
|
||||

|
||||
|
||||
虽然这样能保证内存空间充分使用,并且也没有标记复制算法那么繁杂,但是缺点也是显而易见的,它的**效率比前两者都低**。甚至,由于需要修改对象在内存中的位置,此时程序必须要暂停才可以,在极端情况下,可能会导致整个程序发生停顿(被称为“Stop The World”)。
|
||||
|
||||
所以,我们可以将**标记清除算法和标记整理算法**混合使用,在内存空间还不是很凌乱的时候,采用标记清除算法其实是没有多大问题的,当内存空间凌乱到一定程度后,我们可以进行一次标记整理算法。
|
||||
|
||||
## 垃圾收集器的实现
|
||||
|
||||
### Serial收集器
|
||||
|
||||
- **单线程**,需要STW,新生代:标记复制算法,老年代:标记整理算法
|
||||
- 详情
|
||||
|
||||
这款垃圾收集器也是元老级别的收集器了,在JDK1.3.1之前,是虚拟机新生代区域收集器的唯一选择。这是一款单线程的垃圾收集器,也就是说,当开始进行垃圾回收时,需要**暂停所有的线程**,直到垃圾收集工作结束。它的新生代收集算法采用的是标记复制算法,老年代采用的是标记整理算法。
|
||||
|
||||

|
||||
|
||||
可以看到,当进入到垃圾回收阶段时,所有的用户线程必须等待GC线程完成工作,就相当于你打一把LOL 40分钟,中途每隔1分钟网络就卡5秒钟,可能这时你正在打团,结果你被物理控制直接在那里站了5秒钟,这确实让人难以接受。
|
||||
|
||||
- 虽然缺点很明显,但是优势也是显而易见的:
|
||||
1. 设计简单而高效。
|
||||
2. 在用户的桌面应用场景中,内存一般不大,可以在较短时间内完成垃圾收集,只要不频繁发生,使用串行回收器是可以接受的。
|
||||
|
||||
所以,在客户端模式(一般用于一些桌面级图形化界面应用程序)下的新生代中,默认垃圾收集器至今依然是Serial收集器。我们可以在`java -version`中查看默认的客户端模式:
|
||||
|
||||
- **Client Mode** 优化桌面应用程序,侧重于快速启动和低资源占用。
|
||||
- **Server Mode** 优化服务器端应用程序,侧重于长时间运行中的高性能和高吞吐量。
|
||||
- 不同模式,垃圾回收器不同,内存占用不同
|
||||
|
||||
```Plain
|
||||
openjdk version "1.8.0_322"
|
||||
OpenJDK Runtime Environment (Zulu 8.60.0.21-CA-macos-aarch64) (build 1.8.0_322-b06)
|
||||
OpenJDK 64-Bit Server VM (Zulu 8.60.0.21-CA-macos-aarch64) (build 25.322-b06, mixed mode)
|
||||
```
|
||||
|
||||
我们可以在jvm.cfg文件中切换JRE为Server VM或是Client VM,默认路径为:
|
||||
|
||||
```Plain
|
||||
JDK安装目录/jre/lib/jvm.cfg
|
||||
```
|
||||
|
||||
比如我们需要将当前模式切换为客户端模式,那么我们可以这样编辑:
|
||||
|
||||
```Plain
|
||||
-client KNOWN
|
||||
-server IGNORE
|
||||
```
|
||||
|
||||
|
||||
### ParNew收集器
|
||||
|
||||
- **多线程**,需要STW,用于新生代:标记复制算法
|
||||
- 详情
|
||||
|
||||
- 这款垃圾收集器相当于是Serial收集器的多线程版本,它能够支持**多线程垃圾**收集:
|
||||
|
||||

|
||||
|
||||
- 如何保证线程安全
|
||||
|
||||
### 1. **GC Barrier (垃圾收集屏障)**
|
||||
|
||||
- **概念**:与 Parallel Scavenge 类似,ParNew 也使用 GC Barrier 来同步线程之间的操作,防止在并发垃圾回收过程中发生数据不一致的情况。
|
||||
- **作用**:这些屏障确保了在对象复制和移动的过程中,其他线程的操作不会破坏对象的状态。
|
||||
|
||||
### 2. **卡表 (Card Table)**
|
||||
|
||||
- **概念**:ParNew 同样使用卡表来追踪新生代中的对象引用变化。
|
||||
- **作用**:卡表机制允许垃圾收集器在多线程并发时快速确定哪些内存区域需要重新扫描,减少了不必要的开销,从而保持了线程安全。
|
||||
|
||||
### 3. **写屏障 (Write Barrier)**
|
||||
|
||||
- **概念**:写屏障在 ParNew 中被用于确保对象引用的修改在并行回收时被正确地记录下来。
|
||||
- **作用**:当对象的引用在新生代垃圾回收过程中被修改时,写屏障可以防止引用的状态被多个线程同时修改,确保这些操作的原子性和一致性。
|
||||
|
||||
### 4. **对象头的锁机制**
|
||||
|
||||
- **概念**:ParNew 收集器在并行垃圾回收过程中,也利用对象头中的锁信息来管理对象的并发访问。
|
||||
- **作用**:当多个线程同时访问或修改某个对象时,对象头的锁机制确保只有一个线程可以对其状态进行修改,从而避免数据竞争问题。
|
||||
|
||||
### 5. **停止-the-world (STW) 机制**
|
||||
|
||||
- **概念**:ParNew 收集器在某些阶段仍然会使用 STW 机制来暂停所有应用线程,确保垃圾回收的操作在一个安全的环境下执行。
|
||||
- **作用**:STW 机制确保了复杂操作(如对象复制或移动)可以在不受干扰的情况下进行,从而保证线程安全。
|
||||
|
||||
### 6. **CAS(Compare-And-Swap)操作**
|
||||
|
||||
- **概念**:ParNew 也利用了 CAS 操作来保证某些关键操作的原子性。
|
||||
- **作用**:CAS 操作用于确保标记或更新对象引用时,不会因为并发访问导致数据不一致。
|
||||
|
||||
### 7. **线程本地分配缓冲区 (Thread-Local Allocation Buffers, TLABs)**
|
||||
|
||||
- **概念**:ParNew 收集器中,TLAB 允许每个线程在自己的缓冲区内进行对象分配,从而避免了多个线程在分配对象时的竞争。
|
||||
- **作用**:TLAB 不仅提高了对象分配的效率,还减少了由于并发分配带来的锁争用问题。
|
||||
|
||||
### 8. **工作窃取(Work Stealing)**
|
||||
|
||||
- **概念**:ParNew 收集器使用工作窃取机制来平衡线程的工作负载,防止某些线程过载而其他线程空闲的情况。
|
||||
- **作用**:工作窃取机制提高了垃圾回收过程中的并行性,并减少了线程竞争,从而提高了整体效率和线程安全性。
|
||||
|
||||
除了多线程支持以外,其他内容基本与Serial收集器一致,并且目前某些==JVM默认的服务端模式新生代收集器就是使用的ParNew收集器==。
|
||||
|
||||
|
||||
|
||||
|
||||
### Parallel Scavenge/Parallel Old收集器
|
||||
|
||||
- 多线程,**关注吞吐量**,新生代:标记复制算法,老年代:标记整理算法
|
||||
- 详情
|
||||
|
||||
- Parallel Scavenge同样是一款==面向新生代的垃圾收集器==,同样采用==标记复制算法==实现,在JDK6时也推出了其老年代收集器Parallel Old,采用标记整理算法实现:
|
||||
|
||||

|
||||
|
||||
- 与ParNew收集器不同的是,它会自动衡量一个吞吐量,并根据吞吐量来决定每次垃圾回收的时间,这种自适应机制,能够很好地权衡当前机器的性能,根据性能选择最优方案。
|
||||
- 吞吐量问题
|
||||
该收集器的一个显著特点是它可以通过参数调整,以优化吞吐量(应用程序运行的总时间占总时间的比例)。它允许开发者通过设置 `-XX:MaxGCPauseMillis`(最大 GC 停顿时间)和 `-XX:GCTimeRatio`(GC 时间比例)来控制 GC 的行为,找到停顿时间和吞吐量之间的平衡。
|
||||
|
||||
目前JDK8采用的就是这种 Parallel Scavenge + Parallel Old 的垃圾回收方案。
|
||||
|
||||
|
||||
> [!important] 以上收集器,都会触发
|
||||
>
|
||||
> **Stop-the-World (STW)** 事件,也就是需要**将所有应用线程暂停**。这是为了确保垃圾回收过程中对象的内存状态一致性,防止并发修改导致数据错误或崩溃
|
||||
|
||||
### CMS收集器
|
||||
|
||||
- 基于**标记-清除算法**,以获取最短回收停顿时间为目标,短暂STW
|
||||
- 并发收集,减少停顿时间,工作线程一起运行
|
||||
- 详情
|
||||
|
||||
- 在JDK1.5,HotSpot推出了一款在强交互应用中几乎可认为有划时代意义的垃圾收集器:CMS(Concurrent-Mark-Sweep)收集器,这款收集器是HotSpot虚拟机中第一款真正意义上的**并发**(注意这里的并发和之前的并行是有区别的,并发可以理解为**同时运行用户线程和GC线程**,而并行可以理解为多条GC线程同时工作(线程暂停))收集器,它第一次实现了让垃圾收集线程与用户线程同时工作。
|
||||
|
||||
它主要采用标记清除算法:
|
||||
|
||||

|
||||
|
||||
它的垃圾回收分为4个阶段:
|
||||
|
||||
- 初始标记(**需要暂停用户线程**):这个阶段的主要任务仅仅只是标记出GC Roots能直接关联到的对象,速度比较快,不用担心会停顿太长时间。
|
||||
- 并发标记:从GC Roots的直接关联对象开始遍历整个对象图的过程,这个过程耗时较长但是**不需要停顿用户线程,可以与垃圾收集线程一起并发运行**。
|
||||
- 重新标记(需要暂停用户线程):由于并发标记阶段可能某些用户线程会导致标记产生变得,因此这里需要再次暂停所有线程进行并行标记,这个时间会比初始标记时间长一丢丢。
|
||||
- 并发清除:最后就可以直接将所有标记好的无用对象进行删除,因为这些对象程序中也用不到了,所以可以与用户线程并发运行。
|
||||
|
||||
虽然它的优点非常之大,但是缺点也是显而易见的,我们之前说过,标记清除算法会产生大量的内存碎片,导致可用连续空间逐渐变少,长期这样下来,会有更高的概率触发Full GC,并且在与用户线程并发执行的情况下,也会占用一部分的系统资源,导致用户线程的运行速度一定程度上减慢。
|
||||
|
||||
不过,如果你希望的是最低的GC停顿时间,这款垃圾收集器无疑是最佳选择,不过自从G1收集器问世之后,CMS收集器不再推荐使用了。
|
||||
|
||||
|
||||
### Garbage First (G1) 收集器⭐
|
||||
|
||||
- **堆划分为多个区域(Region)**
|
||||
- 并发标记,基于复制的年轻代回收,基于复制和整理的老年代增量回收
|
||||
- 详情
|
||||
|
||||
- 历史:此垃圾收集器也是一款划时代的垃圾收集器,在JDK7的时候正式走上历史舞台,它是一款主要面向于服务端的垃圾收集器,并且在JDK9时,取代了JDK8默认的 Parallel Scavenge + Parallel Old 的回收方案。
|
||||
- 分区:我们知道,我们的垃圾回收分为`Minor GC`、`Major GC` 和`Full GC`,它们分别对应的是新生代,老年代和整个堆内存的垃圾回收,而G1收集器巧妙地绕过了这些约定,它将整个Java堆划分成`2048`个大小相同的独立`Region`块,每个`Region块`的大小根据堆空间的实际大小而定,整体被控制在1MB到32MB之间,且都为2的N次幂。所有的`Region`大小相同,且在JVM的整个生命周期内不会发生改变。
|
||||
- 那么分出这些`Region`有什么意义呢?每一个`Region`都可以根据需要,自由决定扮演哪个角色(Eden、Survivor和老年代),收集器会根据对应的角色采用不同的回收策略。此外,G1收集器还存在一个Humongous区域,它专门用于存放大对象(一般认为大小超过了Region容量一半的对象为大对象)这样,新生代、老年代在物理上,不再是一个连续的内存区域,而是到处分布的。
|
||||
|
||||

|
||||
|
||||
它的**回收过程与CMS大体类似**:
|
||||
|
||||

|
||||
|
||||
分为以下四个步骤:
|
||||
|
||||
- 初始标记(暂停用户线程):仅仅只是标记一下GC Roots==能直接关联到的对象==,并且修改TAMS指针的值(区分了初始阶段之前之后的对象,之前的对象需要进行分析),让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
|
||||
- 并发标记:从GC Root开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。
|
||||
- 最终标记(暂停用户线程):对用户线程做一个短暂的暂停,用于处理并发标记阶段漏标的那部分对象。
|
||||
- 筛选回收:负责更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多个收集器线程并行完成的。
|
||||
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
{kind=link}
|
After Width: | Height: | Size: 144 KiB |
{kind=link}
|
After Width: | Height: | Size: 160 KiB |
{kind=link}
|
After Width: | Height: | Size: 194 KiB |
{kind=link}
|
After Width: | Height: | Size: 259 KiB |
{kind=link}
|
After Width: | Height: | Size: 211 KiB |
{kind=link}
|
After Width: | Height: | Size: 131 KiB |
{kind=link}
|
After Width: | Height: | Size: 90 KiB |
{kind=link}
|
After Width: | Height: | Size: 158 KiB |
{kind=link}
|
After Width: | Height: | Size: 148 KiB |
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
{kind=link}
|
After Width: | Height: | Size: 246 KiB |
{kind=link}
|
After Width: | Height: | Size: 255 KiB |
{kind=link}
|
After Width: | Height: | Size: 273 KiB |
{kind=link}
|
After Width: | Height: | Size: 113 KiB |
{kind=link}
|
After Width: | Height: | Size: 257 KiB |
{kind=link}
|
After Width: | Height: | Size: 222 KiB |
{kind=link}
|
After Width: | Height: | Size: 219 KiB |